Игорь Кашин, старший разработчик отдела локализации FI
Айрат Кугашев, старший разработчик отдела локализации FI
Новые технологии разработки с использованием SAP HANA
Игорь Кашин, старший разработчик отдела локализации FI
Айрат Кугашев, старший разработчик отдела локализации FI
Компания SAP осознает, что настало время перемен, время новых технологических решений — так у нас появилась SAP HANA. Помимо того, что это новый продукт, который имеет свои преимущества, это еще и «энейблер», позволяющий нам развивать наши технологии и существующие продукты. Порой SAP упрекают, например, в неудобстве интерфейсов, непонятной организации данных и скорости работы. Если проблему скорости мы решаем, просто установив SAP HANA и произведя небольшие изменения в наших исходных кодах, то для остальных проблем нужно найти другое решение.
Сегодняшняя сессия была запланирована как глубокое погружение, но в результате она скорее получилась обзорной, поскольку в неё должен уместиться рассказ про большое число связанных технологий. Начнем с более подробного рассказа о SAP Fiori, точнее, не о Fiori как таковом, а о том, как выглядят Fiori приложения с точки зрения архитектуры. Потом я расскажу о тех вещах, которые помогают нам создавать приложения на Fiori: это SAP HANA Extended Application Services (XS Engine); виртуальная модель данных, являющаяся частью SAP HANA; SAP Smart Business, фреймворк, который позволяет нам быстро создавать в Fiori приложения аналитического типа, я покажу такое приложение, чтобы вы могли оценить его. Потом будет большая тема Core Data Services, которой я коснусь достаточно поверхностно: это не совсем технология сегодняшнего дня, это то, что мы будем использовать уже завтра. Мы только-только начинаем применять Core Data Services внутри компании, но скоро это будет основой многих наших новых приложений, при этом вы можете начать использовать технологию уже сегодня. После этого мы перейдем к обзору изменений, которые появились в ABAP, обсудим расширенный Open SQL и ABAP Managed Database Procedures.
Итак, SAP Fiori. Сам по себе Fiori — современный пользовательский интерфейс, для создания которого применяются актуальные технологии, есть поддержка мобильных устройств и, самое главное, принципиально другой подход к тому, зачем нужны приложения, и как мы ими пользуемся.
Во вчерашнем докладе нашего главы глобализации Фероза говорилось о симплификации. Симплификация внутри SAP не означает, что мы все упрощаем, и пользователи теряют возможность решать сложные задачи. Симплификация означает, что каждый пользователь, который запускает приложение, использует определенный сценарий, соответствующий его роли в компании и, как правило, он не пользуется большей частью возможностей. Получается, что лишние возможности лишь усложняют его работу. Во Fiori функционал разделятся на приложения не только в соответствии с процессами, но и в соответствии с ролью пользователей в этих процессах, в этом и заключается ключевое отличие подхода. С точки зрения пользователя это выглядит как собственная точа запуска точка запуска для сотрудника с определённой ролью, на которой ему всё понятно и нет ничего лишнего. На сегодня уже доступно более 380 приложений, их могут использовать те, у кого установлены SAP Business Suite и SAP HANA. Среди них 116 приложений транзакционных, все остальное — аналитические и информационные. В основном они относятся к модулю финансов, но разработка продолжается, и с каждым днём SAP покрывает всё большую функциональность.
Начнем с краткого обзора архитектуры Fiori: я уже упомянул, что у нас есть разные типы приложений, направленные на разные задачи. Во-первых, это транзакционные приложения, которые служат для того, чтобы вводить информацию в систему, изменять данные какие‑то, обслуживать какие‑то процессы. Яркий пример транзакционного приложения — проводка документа. Во-вторых, у нас есть аналитические приложения, которые нам нужны, если мы хотим посмотреть на какие‑то агрегированные данные, понять общие показатели, и, возможно, иметь какой‑то путь для дальнейшего анализа. В-третьих, есть информационные приложения, или, если более точно, информационные бюллетени. Например, такое приложение может представлять собой карточку контрагента, из которой пользователь может посмотреть всю информацию о нем, перейти в какие‑то связанные с ним функции и видеть все данные в деталях. На сегодняшний день во Fiori аналитические и информационные приложения доступны только для SAP HANA.
Теперь давайте посмотрим на архитектуру этих разных типов приложений и разберемся, почему только часть работает без HANA. Самая простая архитектура у транзакционных приложений, здесь мы видим, что пользователь, используя любое устройство, удобное ему, через http-запрос обращается к front-end серверу. На front-end сервере установлен SAP NetWeaver, который, соответственно, содержит в себе библиотеки для UI5, Fiori, описания UI-приложений и шлюз, на который передается oData-запрос и, соответственно, через oData уже получается результат. Front-end-сервер взаимодействует с back-end-сервером, на котором находится бизнес-логика приложения. Back-end-сервер может работать с любой базой данных.
Когда речь заходит об аналитике, мы хотим использовать все имеющиеся преимущества HANA, а это значит, что у нас появляется другой вариант работы. В зависимости от ситуации аналитическое приложение может работать тем же путём, что и транзакционное, а может использовать SAP HANA XS Engine. Для направления запросов появляется web-диспетчер, который решает, каким способом лучше реализовать каждый конкретный запрос. Сам по себе XS Engine может содержать полностью Fiori приложение, может содержать дополнительные библиотеки. В XS Engine находится виртуальна модель данных, к тому же, например, если мы говорим о Smart Business, то этот фреймворк полностью находится в XS Engine.
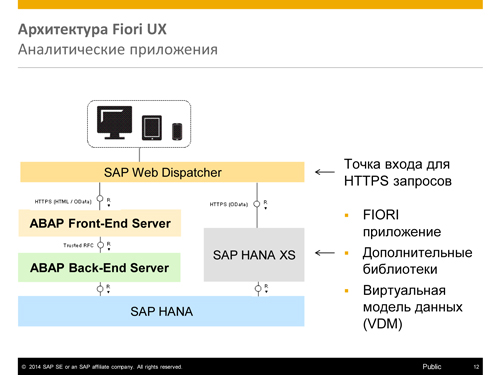
Для информационных приложений также нужна HANA, поскольку для них на back-end-сервере устанавливается дополнительная модель поиска, которая обращается к SAP HANA запросами по протоколу INA.
Давайте разберёмся что такое XS Engine и за счёт чего он позволяет использовать HANA более эффективно? Название XS Engine расшифровывается как HANA Extended Application Services, он включает в себя мини-сервер приложений, мини web-сервер и платформу разработки. Физически XS Engine находится непосредственно в SAP HANA, то есть максимально близко к данным и с максимальными возможностями для бесшовной интеграции, нет дополнительных затрат на пересылку данных, а значит использование дешевле. При этом мы можем разрабатывать любые приложения, которые используют web-интерфейс и приложения, которые взаимодействуют напрямую с SAP HANA, другими словами, практически любые приложения. Кроме этого, для того, чтобы было проще писать oData сервис, существует специальное расширение под названием XS oData, позволяющее взять существующий ракурс или calculation view и объявить доступ к нему. При этом в большинстве случаев отпадает необходимость описывать правила доступа, это быстро и очень удобно.
Технологически для работы с данными в XS Engine доступны SQL, SQL-скрипт, доступен SAP HANA Calculation Engine, который позволяет делать базовые вычисления, и доступна библиотека Application Function Library (набор наиболее востребованных стандартных функций). Для того чтобы управлять потоком данных есть возможность использовать специальную модификацию XML для анализа данных и серверный javascript. Соответственно, пользовательские приложения могут использовать что угодно, но их интерфейс должен быть построен на HTML5, использовать javascript и обращаться к серверу через http-запросы, использование http и HTML5 позволяет выполнять приложения на различных устройствах.
Разграничение прав происходит на уровне Fiori, Fiori это не только наши библиотеки для создание интерфейсов, Fiori подразумевает особую функциональность для работы с ролями. В определение ролей входит описание приложений, которые она может использовать. Соответственно, пользователь не просто не видит эти приложения, но и не может получить относящиеся к ним данные используя XS oData или обычный oData сервис, они просто вернут код отказа. oData расположен на front-end-сервере, а значит отсутствует необходимость двойного ведения ролей.
Перейдем к виртуальной модели данных — VDM. VDM — очень общее название, оно не говорит о том, что это такое, но очень точно определяет, что она делает. VDM — это модель данных, теперь определимся, что такое модель данных. Бизнес-логика описывается экспертами в предметной области, но эксперты не всегда разбираются в технической стороне. Если у нас есть биолог или генный инженер, которому нужно сделать приложение, то ему придётся прийти к программисту и описать на понятном языке что нужно сделать. Проблема в том, что они с программистом говорят на разных языках и донести информацию бывает не так просто. Они оба потратят на общение кучу времени и не факт, что информация будет донесена корректно.
Так как мы хотим использовать по максимуму наших бизнес-экспертов, то заранее договариваемся о терминологии и методологии процессов, это и есть модель данных. Модели данных бывают разных типов: концептуальные, логические и физические. Концептуальная модель подразумевает, что у нас есть какие‑то очень высокоуровневые понятные конструкции, но нет технических ограничений, нет никаких требований к нормализации данных. То есть посмотрел — все понятно, но вот что к чему, как это работает ни малейшего представления. Но детальное понимание и не нужно, такие модели, как правило, предназначены для высшего руководства, людей, которым нужно видеть большую картину на высоком уровне абстракции.
Логические модели данных, к которым относится и виртуальная модель данных в HANA, содержат в себе более специализированные понятия. Но там все еще есть бизнес-наименования, и там все еще нет никакой привязки к технической платформе. Это именно то, что нужно экспертам, которые сразу договорились, что как называть, и как объяснять программистам что требуется.
Программист оперирует уже физической моделью, где у него есть таблица, столбцы, ключи, технические имена, стандарты, которые приняты внутри компании, стандарты, которые приняты в зависимости от платформы и какие‑то технические ограничения.
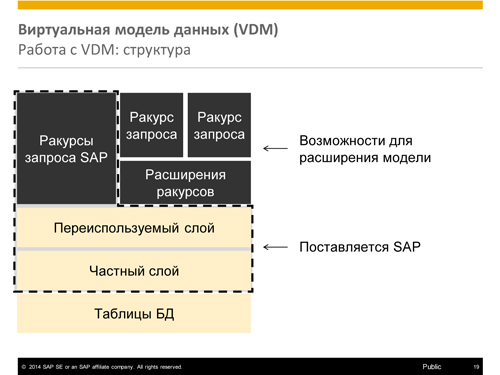
Получается, что виртуальная модель данных нужна для того, чтобы бизнес-эксперт мог работать с данными. В SAP HANA есть набор структурированных ракурсов, а эти структурированные ракурсы составляют часть аналитического каркаса и позволяют получить быстрый и простой доступ к данным.
Если говорить проще, человек, который хочет получить какие‑то аналитические данные из SAP HANA, ищет необходимую ему бизнес-сущность и дальше получает либо какие‑то агрегированные значения, либо то, что ему нужно. Понятно, что логически мы оказываемся ближе к пониманию экспертов, физически у нас эта модель данных лежит рядом с данными.
Технически виртуальная модель данных устроена следующим образом: в базе данных есть физические таблицы, поверх