Представлены новые решения для ускорения работы кластерной платформы Hadoop
Две молодые компании — ScaleOut Software и GridGain — готовы совершить революцию в сфере Big Data, ускорив кластерную платформу Apache Hadoop в десятки раз и оптимизировав её для визуализации аналитических результатов в режиме реального времени.
Две молодые компании — ScaleOut Software и GridGain — готовы совершить революцию в сфере Big Data, ускорив кластерную платформу Apache Hadoop в десятки раз и оптимизировав её для визуализации аналитических результатов в режиме реального времени.
Среди множества решений для Big Data и высокопроизводительных вычислений отмечается устойчивый интерес к развитию методов обработки данных в распределённой оперативной памяти.
Крупные разработчики программного обеспечения для бизнес-аналитики — американская компания SAS и немецкая SAP — недавно объединили свои усилия по созданию новых инструментов, использующих архитектуру In-Memory.
Свой вариант подобного ускорения работы реляционной системы управления базами данных DB2 разрабатывает и IBM, но куда интереснее сейчас наблюдать за успехами менее крупных игроков.
Типичный объём оперативной памяти в кластерах под управлением hServer V2 от ScaleOut Software и GridGain 5.2 составляет терабайт и более, а их дисковая подсистема максимально редуцирована и служит в основном для хранения системных данных.
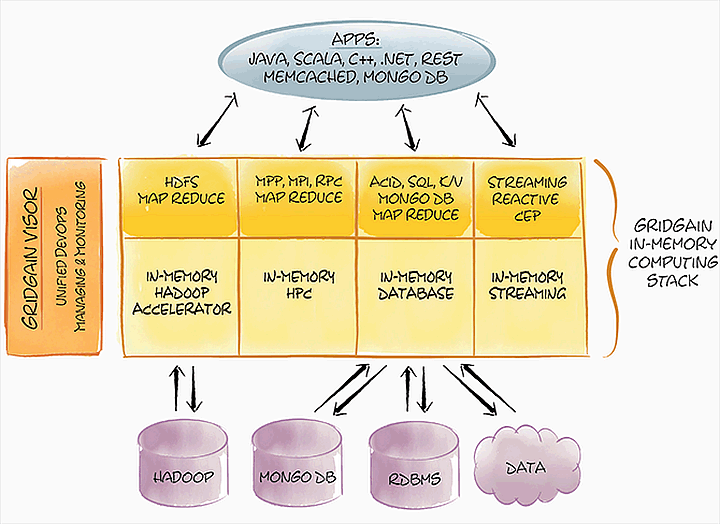
Схема работы программных инструментов GridGain с данными в оперативной памяти (изображение: gridgain.com).
Ведущий аналитик консалтинговой фирмы Ovum Мэдан Шеина (Madan Sheina) так оценивает перспективы обоих продуктов:
«Я вижу технологии GridGain и ScaleOut как ускорители для Hadoop. Обе позволяют использовать обработку больших объёмов данных по алгоритму MapReduce в распределённой оперативной памяти без предварительного считывания их из файловой системы HDFS. Это ускоряет обновление данных и превращает Hadoop в платформу анализа в реальном времени».
Представленная недавно обновленная версия hServer V2 уже содержит дистрибутив Hadoop и тем самым экономит время развёртывания.
Генеральный директор ScaleOut Билл Бэйн (Bill Bain) поясняет некоторые детали:
«Можно ускорить выполнение MapReduce, используя вместо встроенного планировщика Hadoop нашу платформу параллельных вычислений. С ней задания MapReduce формируются буквально за секунду вместо обычных тридцати».
Альтернативная платформа облачных вычислений с открытым исходным кодом GridGain также реализует выполнение MapReduce для данных в распределённой оперативной памяти.
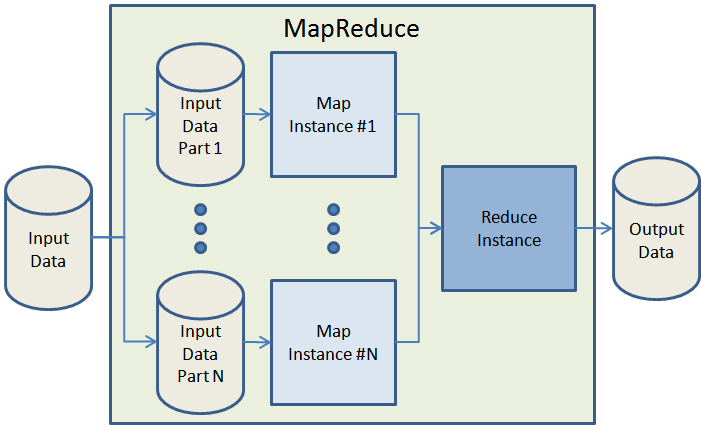
Схема алгоритма MapReduce (изображение: Amazon).
По сравнению с чистой Apache Hadoop GridGain эффективнее работает с меньшим объёмом данных, но оптимизирована для более интенсивных вычислений. Сегодня GridGain — это зрелый программный комплекс, в котором широко представлены различные утилиты. Среди них инструменты мониторинга, балансировки, автоматического восстановления и другие.
Новый продукт GridGain’s In-Memory Database 5.2 предназначен для обработки большого количества одновременных транзакций (до миллиарда в секунду) в режиме реального времени. В основном речь идёт о статистической финансовой информации, такой как динамика продаж и текущие банковские операции.
Экономическая целесообразность хранения данных в оперативной памяти вместо дисковых массивов обусловлена постепенным снижением цен на модули RAM. Даже после пожара на заводе SK Hynix Semiconductor они остаются весьма демократичными.
Другим стимулирующим фактором разработчики называют желание иметь максимально унифицированную архитектуру ИТ-инфраструктуры без необходимости учитывать ограничения различных файловых систем и пропускной способности дисковых интерфейсов.