Использование возможностей SAP HANA в области аналитики и анализа текстов
Автор описывает функцию аналитики и анализа текстов SAP HANA для решения важных задач с помощью необработанных данных. В статье рассматриваются возможности получения важной информации с помощью этой функции при работе со специфичными для контента значениями: эмоции, структура поведения и релевантность.
|
Ключевое понятие |
|
SAP HANA предоставляет единую платформу для извлечения и анализа большого объема структурированных и неструктурированных данных в реальном времени из различных источников: социальные сети, блоги, онлайн-обзоры, сообщения электронной почты и обсуждения на форумах. Анализ информации дает ответы на множество специфичных вопросов, позволяет увеличить прибыль и способствует принятию выверенных и своевременных решений. |
Аннотация
Автор описывает функцию аналитики и анализа текстов SAP HANA для решения важных задач с помощью необработанных данных. В статье рассматриваются возможности получения важной информации с помощью этой функции при работе со специфичными для контента значениями: эмоции, структура поведения и релевантность.
Сегодня число источников данных и их объем растут с необычайной скоростью. Мы научились без труда анализировать структурированные данные (например, показатели продаж), но нам становится все сложнее услышать мнение клиента. SAP HANA позволяет преобразовать неструктурированную обратную связь от клиентов на разных языках из множества источников в ценную информацию, на основе которой вы сможете продумать свои действия. Имея в своем распоряжении такую информацию, вы можете создавать и модернизировать кампании, анализировать текущие настроения клиентов и тенденции, запускать новые продукты и корректировать цены.
Более того, располагая ценной информацией, можно разрабатывать таргетированный контент для роста продаж, изменения проблемного поведения клиентов и оценки их настроений. Одним из примеров текстового анализа является использование анализа тональности высказываний на выборах для определения настроений избирателей.
Анализ текста включает в себя определение паттернов, тегирование или аннотирование, извлечение информации, применение способов анализа, интерпретации и представления данных, включая анализ ссылок и связей, а также визуализацию. Целью является преобразование сырого текста в данные для анализа.
SAP HANA обеспечивает необходимую гибкость для выполнения анализа текста и аналитических действий на одной платформе. массивы данных в SAP HANA хранятся в единой базе данных, что экономит время и затраты, а также увеличивает производительность. В моем примере анализ текста выполняется на материале коротких сообщений (твитов) из социальной сети Twitter с целью выявления тональности высказываний клиентов. Помимо этого, создается визуальное представление данных.
Для выполнения текстового анализа с помощью SAP HANA применяются следующие шаги:
- Загрузка данных в SAP HANA
- Конфигурирование текстового анализа и создание пользовательского словаря, если существующий не удовлетворяет требованиям
- Создание полнотекстового индекса и модели
- Создание визуализаций
Шаг 1. Загрузка данных в SAP HANA
В рассматриваемом примере данные Twitter были извлечены в файл Excel на рабочем столе посредством API поиска. Далее файл был загружен в SAP HANA с помощью Python Open Database Connectivity (PYODBC). Это самый простой способ подключения к SAP HANA через Open Database Connectivity (ODBC).
Наличие драйвера SAP HANA Database Open Database Connectivity (HDBODBC) является обязательным условием для загрузки данных на платформу SAP HANA с использованием Python. Пользователи могут загружать данные с помощью различных способов предоставления данных: SAP Landscape Transformation Replication Server (SLT) и SAP Data Services. Другие способы описаны в следующих статьях:
- Перенос данных в SAP HANA с помощью SDA и BODS
- Выбор подходящего инструмента SAP HANA для загрузки данных
- Загрузка данных в SAP HANA Studio
Драйвер устанавливается с помощью клиента SAP HANA. Для проверки наличия драйвера в администраторе источников данных ODBC ноутбука (Рис. 1) выберите в меню «Start > Control Panel > System & Security > Administrative Tools > ODBC > System DSN» (Пуск > Панель управления > Система и безопасность > Администрирование > ODBC > Системный DSN).
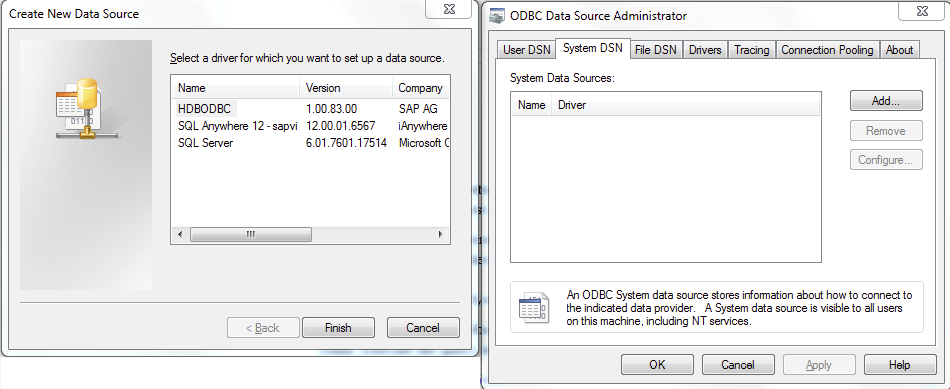
Рис. 1. Драйвер HDBODBC
Перед выполнением скрипта на Python проверьте наличие в SAP HANA таблицы со столбцами «TEXT_ANALYSIS», «PRODUCT» с неструктурированными данными. Выполните запрос (Рис. 2) в консоли SQL в системе SAP HANA для создания таблицы с необходимыми столбцами. Таблица представлена в папке таблиц схемы TEXT_ANALYSIS в разделе «Catalog in Systems» (Каталог в системах), см. Рис. 3.

Рис. 2. Создание запроса к таблице
Оформите подписку sappro и получите полный доступ к материалам SAPPRO
Оформить подпискуУ вас уже есть подписка?
Войти