Введение в SAP Predictive Analytics 2.0 и инструменты прогнозирования SAP HANA
В своем эксклюзивном отчете Хиллари Блисс вводит нас в мир инструментов прогнозирования SAP. Особое внимание уделяется новому решению SAP Predictive Analytics 2.0 и его взаимосвязям с SAP HANA и SAP Lumira. Автор демонстрирует важность общих концепций прогнозного моделирования, а затем применяет эти концепции в рамках более широкой дискуссии об архитектуре и функциях SAP Predictive Analytics. Наконец, читатели смогут узнать о новых инструментах прогнозирования SAP, выход которых запланирован на ближайшее будущее.
Ключевое понятие
Прогнозная модель — это уравнение, алгоритм или набор правил, которые используются для прогнозирования результата на основе входных данных. Прогнозной моделью может быть простой набор бизнес-правил, основанных на наблюдениях за прошлые периоды. Однако для создания более точных и статистически строгих прогнозов часто используются статистические алгоритмы для разработки статистического уравнения.
Система SAP Predictive Analysis, предшественник SAP Predictive Analytics Expert Analytics, вышла в составе пакета SAP BusinessObjects BI в 2012 году. В этой системе были добавлены новые функции к существующему набору инструментов BusinessObjects. Expert Analytics расширяет возможности визуализированной аналитики в SAP Lumira и предоставляет новые функции прогнозирования на базе алгоритмов с открытым исходным кодом на языке R и алгоритмов, разработанных SAP. В сентябре 2013 года компания SAP приобрела Automated Analytics (прежнее название KXEN) с базой лояльных пользователей, выбравших этот удобный и мощный инструмент прогнозирования.
В этом подробном отчете сначала будет представлен обзор общего процесса прогнозного моделирования. Далее мы подробно рассмотрим механизмы моделирования в SAP Predictive Analytics 2.0, а также функции и возможности этого программного обеспечения. Помимо этого, в статье описана интеграция Expert Analytics с SAP Lumira и SAP HANA, а также запланированные этапы развития на 2015 год и далее.
Примечание.
Данная статья является дополненной версией предыдущей статьи Хиллари Введение в SAP Predictive Analysis и интеграция с SAP HANA, опубликованной в июне 2013 года.
Примечание.
В следующем разделе статьи подробно рассматриваются базовые элементы прогнозного анализа и моделирования. Если вы уже хорошо знакомы с этими понятиями, переходите сразу к разделу «Предпосылки и навыки для проведения прогнозного анализа».
Обзор прогнозного моделирования
Прогнозные модели важны, поскольку позволяют компаниям прогнозировать результаты реализации альтернативных стратегий до их фактического применения и определять наиболее эффективный способ распределения ресурсов, например, выделенных на маркетинг денежных средств или рабочих часов. Распространенные области применения прогнозных моделей:
- Модели отклика и увеличения объемов продаж позволяют прогнозировать, какие клиенты с большей вероятностью ответят (или будут активнее отвечать с течением времени) на маркетинговый запрос (рассылка по электронной почте, адресная почтовая рассылка или рекламные мероприятия).
- Модели расширения предложений и продаж по более высокой цене позволяют прогнозировать, какие предложения по продуктам приведут к росту продаж или к дополнительным продажам у данного клиента.
- Модели сохранения и потерь позволяют прогнозировать, какие клиенты с большей вероятностью уйдут или прекратят покупки в ближайшем будущем, а также определить меры, которые позволят снизить вероятность ухода клиентов.
- Сегментация позволяет прогнозировать клиентов с аналогичным поведением и операциями по маркетинговым или сервисным предложениям.
- Модели мошеннического поведения позволяют прогнозировать, какие транзакции, претензии и варианты взаимодействия с наибольшей вероятностью окажутся мошенническими или потребуют более пристального рассмотрения.
Не следует путать бизнес-задачи, которые могут быть решены с использованием моделей прогнозирования, с прогнозными алгоритмами. Каждую из указанных выше задач можно решить с помощью ряда различных алгоритмов. Понимание признаков бизнес-проблемы и выбор для данных наиболее подходящего алгоритма прогнозирования в рамках разработки статистических моделей часто требует в большей степени чутья, чем специальных знаний.
Допустим, компании требуется спрогнозировать простой двоичный результат (например, примет ли клиент предложение). В этом случае специалист по моделированию может применить дерево принятия решений, наивный классификатор Байеса или регрессионную логистическую модель. Каждая из этих методологий прогнозирования имеет свои преимущества и недостатки с точки зрения простоты реализации, точности результатов, достоверности и сложности разработки.
Ценность прогнозного моделирования для каждой компании будет разной, но несложно рассчитать ценность точного прогнозирования результатов. С точки зрения маркетинга распределение ограниченных маркетинговых ресурсов между клиентами, которые с наибольшей вероятностью ответят на предложение, может увеличить процент положительных ответов и одновременно сократить расходы, что часто соответствует возврату от вложений в размере миллионов долларов в год.
Кроме того, с помощью прогнозных моделей компании могут тестировать множество предложений в среде моделирования для предсказания возможной прибыли, вместо того, чтобы выбирать между альтернативными вариантами, доверившись интуиции. Для компаний, оказывающих финансовые услуги, или страховых фирм точное прогнозирование по клиентам вероятности обращения за возмещением или невозврата займа означает более точную оценку рисков и более высокую вероятность привлечения наиболее выгодных клиентов. Аналогично стандартные и количественно определяемые бизнес-правила для создания таких моделей позволяют компаниям более оперативно реагировать на изменения на рынке и в случае выявления изменений создавать модели, отражающие меняющуюся бизнес-среду.
Как правило, компании начинают разрабатывать модели прогнозирования для конкретной сферы или отдела и быстро находят множество возможностей для использования аналогичных средств в других функциональных сферах.
Поток данных в процессе моделирования
На рис. 1 представлен обзор потока данных в процессе моделирования.
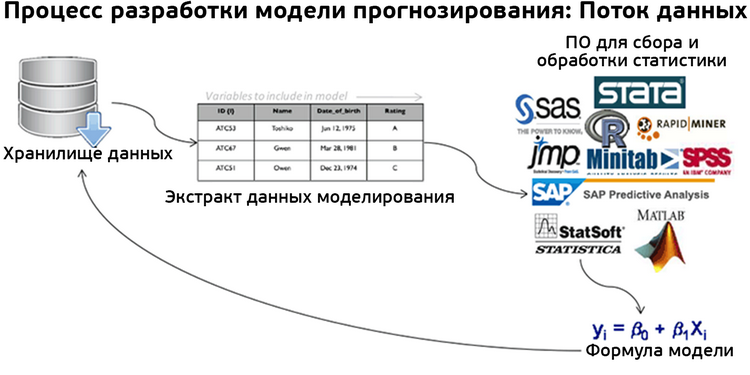
Рис. 1. Поток данных в прогнозном моделировании
Моделируемые данные извлекаются из хранилища и часто предварительно преобразуются для переноса в инструмент прогнозирования. Данные переносятся посредством экспорта текстового файла или через прямое подключение к базе данных. В идеале инструмент прогнозного моделирования позволяет обращаться к данным и записывать их обратно в хранилище. Часто процесс переноса данных является итеративным, поскольку экстракт данных моделирования корректируется с добавлением, удалением или изменением переменных.
Несмотря на то, что программное обеспечение играет важную роль в процессе моделирования, выполнение прогнозных алгоритмов фактически является лишь малой частью всего процесса создания модели. В своих маркетинговых материалах к инструментам прогнозирования компания SAP утверждает, что создание прогнозных моделей составляет лишь 20 % от общего времени и трудозатрат в процессе моделирования. Для манипулирования данными, их изучения и реализации требуется больше ресурсов, чем для фактического создания модели.
Таким образом, выбор инструмента моделирования, который включает в себя элементы манипулирования данными и изучения данных, упрощает реализацию и интегрируется с источниками данных, сокращает число операций по переносу данных и ускоряет реализацию результатов прогнозирования.
Общий процесс создания прогнозных моделей состоит из следующих шагов:
Шаг 1. Определение целей прогнозной модели.
Шаг 2. Выбор подходящего инструмента моделирования.
Шаг 3. Предварительный анализ данных и изучение полученных данных.
Шаг 4. Разработка модели (включая выбор прогнозного алгоритма и переменных прогноза для добавления в модель и оценки точности модели и ее адекватности).
Шаг 5. Реализация выбранной модели.
Шаг 6. Изменение и доболнительное обучение модели при необходимости.
Рассмотрим эти шаги более подробно.
Шаг 1. Определение целей прогнозной модели
Все руководители сталкиваются с проблемами, которые заставляют их не спать по ночам, думая о будущем компании или отрасли. Часто оказывается непросто найти пути анализа для конкретного бизнес-решения используя используя результаты прогнозной аналитики, поскольку аналитик, обобщая и изучая огромные объемы имеющихся данных, может упустить из виду возможности, реализация которых принесла бы организации прибыль. При поддержке руководства аналитик должен определить цели анализа и желательный результат. Для выполнения этой задачи может потребоваться ответить на следующие вопросы:
- Какие клиенты с наибольшей вероятностью откликнутся на маркетинговый запрос?
- Какие клиенты могут в скором времени отменить подписку или прекратить покупки?
- Какие предложения, среда, визуальная информация или прочие входные данные способствуют увеличению суммы покупки?
- У каких клиентов могут произойти события в жизни, мотивирующие их на покупку?
На основе ответов можно определить результаты, которые предполагают совершение конкретных действий, ведущих к получению прибыли.
Наконец, при разработке целей анализа группы по аналитике и руководство должны обеспечить наличие достаточных данных для построения моделей. Например, компания, у которой нет клиентской базы, не может разрабатывать сегменты клиентов или определять клиентов, работа с которыми принесет наибольшую прибыль. Страховая компания, которой требуется создать модель выявления мошеннических правопритязаний, должна иметь средства предоставления или определения набора таких правонарушенийв прошлом. Прогнозная модель — не волшебная палочка, которая наколдует вам аналитическую информацию из воздуха. Это система правил или уравнений, которые позволяют синтезировать опыт прошлых периодов для прогнозирования наиболее вероятных результатов тех или иных действий в будущем.
К сожалению, эту часть процесса часто игнорируют, упуская время и возможности, а на более позднем этапе выясняется, что специалисту по моделированию недостаточно данных для выполнения анализа.
Несмотря на то, что ни один инструмент не сможет выбрать самую лучшую бизнес-стратегию и обсудить с группами по аналитике требования к моделям для реализации этой стратегии, простые средства визуализации данных и инструменты BI могут помочь вам выявить тенденции и предварительную информацию для выбора направления прогнозного анализа. Эффективный опыт BI и удобные для пользователей инструменты запроса позволяют выявить области для возможных улучшений и быстро оценить достаточность данных для создания моделей, чтобы ускорить выполнение первого шага процесса моделирования.
Источник данных
Помимо формулирования бизнес-целей, первый шаг должен включать в себя план получения данных, необходимых для анализа. В немалой степени успех проекта аналитики зависит от наборов данных, которые используются для создания информации для прогнозирования. Для создания эффективного набора данных для моделирования требуется не только тщательно продумать его структуру, но и обеспечить плодотворное сотрудничество понимающих принципы работы с данными предметных экспертов, технических специалистов, которые выполняют фактическое наполнение и составление наборов, а также специалистов по аналитике, которые используют данные и строят модели.
В идеале организация должна располагать хранилищем с данными из всех сфер, с которыми работает компания, загруженными в центральное хранилище в унифицированном формате. Как правило, система отчетов BI предприятия (например, BusinessObjects) упрощает для бизнес-пользователей обработку отчетности и получение доступа к данным. Иногда для обеспечения достаточной степени детализации данных для моделирования требуется извлечь данные непосредственно из хранилища данных, а не из предварительно агрегированных витрин для отчетности.
Шаг 2. Выбор подходящего инструмента моделирования
При оценке инструментов прогнозирования специалисты по моделированию должны учитывать особенности и требования нескольких функциональных сфер. Решение принимается исходя из соответствия возможностей инструмента организационным требованиям и бюджета. В этом разделе рассматриваются ключевые функциональные сферы, которые следует учитывать в процессе выбора инструмента.
Доступ к данным
Как было сказано выше, на создание файла в процессе моделирования часто уходит много времени, поэтому для ускорения этого процесса важно обеспечить инструменту моделирования доступ к данным. Ответьте на следующие вопросы:
- Как данные для моделирования импортируются в инструмент?
- Возможно ли обращение к базам данных напрямую или данные придется переносить исключительно через плоские файлы?
- Поддерживает ли инструмент запись результатов или моделей в базу данных?
Манипулирование данными
К манипулированию данными относится сортировка, группирование, изменение значений и вычисления по существующим полям данных. Если в процесс разработки модели входит оценка и, возможно, изменение полей в базе данных, такая функциональность может ускорить создание модели и позволит не возвращаться каждый раз к созданию нового экстракта из исходной системы. Однако если невозможно экспортировать или задокументировать правила такого изменения, необходимо создавать их заново в любой системе, которая будет оценивать модель.
Архитектура и вычислительная мощность системы
Для выполнения некоторых прогнозных алгоритмов требуется значительная вычислительная мощность, поскольку для определения оптимальных моделей часто требуется итеративное прохождение данных множество раз. Поскольку объемы доступных данных растут и компаниям требуется анализировать большие данные, крайне важной становится способность инструмента прогнозирования обрабатывать большие наборы данных. В результате организациям приходится выбирать между инструментами, установленными на локальном компьютере пользователя, и инструментами, которые могут обрабатывать данные на сервере. Локальные клиентские инструменты можно быстро развернуть, они не требуют выделенного оборудования, однако объем данных, который они способны обработать, весьма ограничен. Серверные инструменты, как правило, работают на выделенном оборудовании, более сложны с точки зрения установки и ведения, но позволяют обрабатывать большие данные и совместно работать с ресурсами большому числу пользователей.
Пользовательские интерфейсы
Интерфейсы инструментов прогнозирования сильно различаются между собой. Здесь встречаются удобные для пользователей интерфейсы, интерфейсы на основе функции перетаскивания и интерфейсы, работающие только с кодом. У некоторых инструментов интерфейс вообще отсутствует, и они выполняют только пакетные задания, отправленные удаленно. Инструменты, работающие только на базе кода, часто предоставляют больше функциональных возможностей и имеют обширные библиотеки для прогнозирования, но требуют более длительной разработки и большего объема технических ресурсов для работы. Решения с графическим пользовательским интерфейсом иногда требуют для управления меньше технических ресурсов и могут ускорить процесс создания модели.
Прогнозные алгоритмы
Каждый инструмент предлагает свою библиотеку прогнозных алгоритмов. Несмотря на то, что существует огромное число алгоритмов, большинство организаций могут выполнить разнообразные аналитически задачи посредством ограниченного набора инструментов на базе всего нескольких алгоритмов для каждого варианта анализа классификации, кластеризации, регрессии и временных рядов. Однако важно еще до выбора инструмента определить цели или типы моделей, которые планирует создать организация, чтобы затем выбрать инструмент, предоставляющий все необходимые функциональные возможности. Например, если организация покупает инструмент прогнозирования исключительно с целью разработки прогнозов по продажам, следует выбрать решение, предназначенное именно для этой области и обладающее специальными возможностями для учета сезонности и периодических событий. Если же компания собирается анализировать поведение клиентов, ей потребуется целый ряд различных инструментов: кластеризация, деревья принятия решений и, возможно, регрессионные алгоритмы.
Особенности оценки моделей
Чтобы выбрать подходящую модель, выполняйте оценку моделей и сравнение альтернативных вариантов. Для ускорения процесса разработки и выбора решения используйте инструменты сравнения. Инструменты оценки моделей предоставляют автоматизированные средства визуализации диаграмм точности прогнозов, анализа остатков и доверительных интервалов для коэффициентов и прогнозируемых значений. Обзор инструментов прогнозирования представлен в выноске «Доступные на рынке инструменты прогнозирования».
Особенности реализации и ведения моделей
После выбора модели компании, как правило, стремятся как можно скорее провести ее развертывание. В зависимости от потребностей организации это может означать просто прикрепить оценку модели к небольшому набору данных. Однако во многих случаях организации требуется возможность вызова модели оценки по запросу. Для этого необходимо написать алгоритм оценки (а не просто определить значения по баллам) в базе данных.
Ускорить этот процесс помогут инструменты прогнозирования с возможностью публикации алгоритмов в базе данных посредством хранимой процедуры, вызова функции или вставки в вызываемый блок кода. В зависимости от сложности алгоритма оценки для расчета коэффициентов и программирования функции оценки может потребоваться много времени. Кроме того, если данные были обработаны инструментом моделирования, возможность экспорта этих правил или их включения в алгоритм оценки значительно сократит время на внедрение.
Доступные на рынке инструменты прогнозирования
Востребованность инструментов прогнозирования растет, поставщики программного обеспечения упорно работают, чтобы не отстать от растущих запросов пользователей к мощности обработки данных и расширению функциональности в удобном интерфейсе. В Википедии можно изучить достаточно полное сравнение статистических пакетов. Блогер Роберт А. Мюнхен опубликовал статью о популярности программных средств для анализа данных, в которой дан обзор различных инструментов на рынке. Согласно его исследованию, язык программирования R является одним из наиболее популярных среди прогнозных аналитиков пакетов для обработки статистических данных. Сфера использования языка R стремительно расширяется последние несколько лет.
Коммерческое программное обеспечение чаще используется бизнес-организациями, а программное обеспечение с открытым кодом — учеными и исследователями. Однако на фоне роста цен на лицензии программного обеспечения и распространения программ с открытым кодом многие организации переходят на инструменты с открытым исходным кодом, например, на языке R. Ниже в этой статье мы остановимся на языке R подробнее.
Далее приводится список аспектов, которые следует учитывать организации при выборе нового инструмента аналитики. После того, как будут четко сформулированы аналитические цели, компания должна определить, какой инструмент максимально соответствует требованиям проекта и долгосрочным целям организации.
Инструменты с узким набором алгоритмов
Как правило, поставщики стремятся предоставлять в инструментах полный набор алгоритмов. Однако существуют узкоспециализированные инструменты, максимально эффективно выполняющие один алгоритм или группу алгоритмов. Часто удобство использования и функции визуализации превосходят возможности полнофункциональных систем. Но вы сможете работать только с одним типом алгоритмов, например, с деревьями принятия решений.
Полнофункциональные инструменты на базе кода
Для работы с большинством комплексных инструментов, предоставляющих доступ к широчайшему диапазону средств диагностики и алгоритмов моделирования, пользователи, как правило, должны обладать глубокими познаниями в области статистики и написания кода. Часто эти инструменты используют полнофункциональные языки программирования и поэтому могут выполнять всю необходимую обработку данных и создавать любые алгоритмы, если их еще нет в их библиотеке кодов. Такие инструменты отличаются особенной гибкостью с точки зрения подготовки данных, прогнозных алгоритмов и оценки моделей, но недостаточно удобны в использовании. У них крутая кривая обучения и сложности с созданием визуализаций.
Облачные решения
Последними новинками на рынке являются облачные решения для прогнозирования с веб-интерфейсами моделирования, хранением и обработкой данных в облаке и моделью хранения данных, разработки моделей и прогнозирования с оплатой за байт или балл.
Шаг 3. Предварительный анализ данных и изучение доступных данных
В процесс анализа данных входит оценка всех доступных для моделирования элементов данных и выбор элементов для включения в анализ. Сюда относится изучение распределения значений в атрибуте, определение их связей с переменной отклика и оценка качества каждого атрибута. Например, выглядят ли значения более или менее точными? Для какого процента наблюдений заполняется эта переменная? Распределяются ли данные по возможным значениям?
Здесь может потребоваться создать новые переменные или изменить определения существующих переменных. Результатом этого процесса анализа является компактный список прогнозных переменных высокой эффективности.
Шаг 4. Разработка модели
Структура набора данных для моделирования часто отличается от стандартного способа организации данных в хранилище или витрине для отчетности. Поэтому много времени и сил в процессе создания модели уходит на проектирование, вычисление и тестирование экстракта данных. В маркетинговых материалах к инструментам прогнозирования SAP указывает, что на получение доступа к данным и выполнение подготовительных шагов требуется 36 % от общего времени, затраченного на разработку модели.
В реальной ситуации извлечение набора данных для моделирования является итеративным процессом, а сроки выполнения процесса моделирования могут быть существенно увеличены в случае необходимости импорта нового файла при каждом изменении поля прогноза. Инструменты с прямым подключением к источнику данных или возможностью манипуляций с входным файлом в инструменте моделирования значительно сокращают объем работ по подготовке данных в процессе моделирования.
Формат наборов данных для моделирования зависит от желательного результата и входных требований к применяемому алгоритму моделирования. Например, если цель — прогноз по ежедневным продажам в Магазине А, перед отправкой в прогнозный алгоритм данные необходимо агрегировать до дневного уровня только по Магазину А. Аналогично для прогнозирования вероятности совершения покупки клиентом требуются данные на уровне клиента, например, одна строка на клиента с отдельными атрибутами для описания демографических признаков и долларовой суммы покупок за последние 6, 12 и 18 месяцев.
Разработка набора данных для моделирования и выбор переменных для включения в модель часто представляет собой итеративный процесс. Например, даст ли объединение клиентов в группы по 15 и 30 лет такой же точный прогноз, как и объединение в группы по 15–20, 21–25 и 26–30 лет? Адаптация и повторная оценка результатов займет меньше времени, если изменения данных будут выполняться в инструменте моделирования. В этом случае вам не придется возвращаться в базу данных, извлекать другой экстракт для моделирования с новыми переменными и снова импортировать его в инструмент моделирования.
Процесс разработки модели предполагает постоянное возвращение к наборам прогнозирующих параметров, алгоритмов моделирования и входным наборам данных до тех пор, пока не будет получен приемлемый результат. Здесь важно найти верный баланс между сложностью модели и точностью прогнозов. Для сравнения и оценки версий модели применяются баллы и данные независимой оценки, при которой учитывается соответствие и точность показателей в сравнении с учебным набором данных, а также сравнивается точность между наборами прогнозирующих параметров или алгоритмов моделирования.
Шаг 5. Реализация выбранной модели
После того, как группы аналитиков и руководства выберут окончательный вариант модели по результатам оценки, соответствию бизнес-требованиям и отраслевым знаниям, они должны сделать формы или результаты модели доступными в продуктивных приложениях. В процесс реализации модели может входить оценка фиксированной группы клиентов или запись прогноза продаж на следующий год в базу данных бюджета. Чаще требуется внедрить в базу данных алгоритм оценки полученной модели или установить приложение оценки в реальном времени для определения спрогнозированного результата для любых данных по запросу. В качестве примера можно привести модель сегментации клиентов, в которой всех новых клиентов необходимо присваивать сегменту при добавлении в базу данных.
Шаг 6. Изменение и дополнительное обучение модели при необходимости
Как и другие бизнес-правила и цели, модели прогнозирования требуют ведения и мониторинга с точки зрения релевантности и точности. Со временем эффективность моделей может снижаться вследствие изменений среды, например, смены экономической ситуации, изменений в продуктах или тенденций в поведении покупателей. Если в результате изменений в процедуре или модели данных становится недоступным или менее точным определенный фрагмент данных, использовавшийся как прогнозирующий параметр, модель может оказаться неадекватной. Таким образом, даже после внедрения модели и подтверждения корректности ее работы требуется ее регулярный мониторинг для отслеживания точности прогнозов и релевантности входных данных.
Также модели необходимо периодически подгонять (пересчитывать коэффициенты по новым данным) или реструктурировать (изменять список прогнозирующих параметров и определение входных переменных или даже использовать другие прогнозные алгоритмы). Например, если компания, работавшая только с одним штатом, внезапно расширяет свою деятельность и начинает работать в новом регионе, модель уже не будет точно прогнозировать поведение клиентов из другого региона по данным, специфичным для одного штата. Эту модель необходимо адаптировать или создать новую модель с использованием данных нового региона, как только компания такие данные получит.
Предпосылки и навыки для проведения прогнозного анализа
Компания SAP разработала решение Expert Analytics как некоторое расширение к продукту SAP Lumira. В Expert Analytics доступны все функциональные возможности SAP Lumira (получение данных, их обработка, формулы, средства визуализации и обогащение метаданных) с дополнительной вкладкой Predict (Прогноз), которая отображается между вкладками Prepare (Подготовка) и Visualize (Визуализация) в стандартной системе SAP Lumira. На вкладке Predict (Прогноз) доступны все функции Expert Analytics, а также прогнозные алгоритмы, аналитика по результатам визуализации и средства управления моделями.
SAP позиционирует SAP Lumira и Expert Analytics как пакет решений для визуализации и анализа. Эти инструменты предоставляют корпоративное решение, в котором пользователи бизнес-аналитики и специалисты по обработке данных, применяющие Expert Analytics для разработки и сборки моделей, могут использовать файлы в собственном формате SAP *.lums совместно с бизнес-пользователями и менеджерами. (Эти пользователи и менеджеры могут иметь доступ только к разделам Lumira в инструменте.) С помощью пакета решений эти группы могут обмениваться ценными сведениями, информацией и результатами, а также быстро и эффективно развертывать результаты и модели действенной аналитики в других инструментах пакетов SAP и BusinessObjects.
Решение Expert Analytics дополняет SAP HANA. Однако работать с Expert Analytics можно и без SAP HANA. Expert Analytics устанавливается на компьютере пользователя и обращается к данным для обработки с рабочей станции (из подключения CSV, Microsoft Excel или Java Database Connectivity (JDBC) к базе данных) или в SAP HANA. Для обработки в автономном режиме Expert Analytics использует локальную систему SAP Sybase IQ (колоночная база данных в оперативной памяти), в которой хранятся и обрабатываются данные для прогноза. Компонент Predictive Analysis доступен в составе настольной системы SAP Predictive Analytics и клиентских пакетов установки, большинство из которых можно установить в считанные минуты. В Expert Analytics включен инструмент установки для загрузки требуемых компонентов R для офлайн-обработки в SAP HANA. Expert Analytics работает на компьютерах с ОС Windows 7 или 8 без каких-либо других инструментов SAP.
Целевым пользователем Predictive Analysis является член группы, которому требуется получать из данных прогнозные выводы. Этот сотрудник может быть специалистом по обработке данных, который ежедневно работает с инструментом обработки статистики на основе кода, или бизнес-аналитиком, хорошо знающим фронтэнд-инструменты BusinessObjects. Несмотря на то, что компания SAP ранее позиционировала систему Expert Analytics как инструмент прогнозирования для широкого круга пользователей, однако более глубоко понимать результаты и более эффективно оперировать с ними смогут сотрудники, имеющие хотя бы небольшой опыт работы с техниками прогнозирования и знакомые с терминологией в сфере статистики. Вероятно, в будущем после ряда обновлений целевая аудитория этого решения вырастет на обоих концах спектра. По мере добавления функций и алгоритмов все больше специалистов по работе с данными смогут перейти с инструментов статистического анализа на основе кода на Expert Analytics для выполнения всех видов анализа. SAP также планирует интегрировать больше путей для направляемого анализа, что сделает инструмент более удобным для бизнес-пользователей без опыта работы со статистикой.
Механизмы моделирования
Expert Analytics работает с несколькими механизмами моделирования. При разработке предшествующей системы, Predictive Analysis, SAP в качестве базового прогнозного механизма использовала сочетание собственных алгоритмов и алгоритмов с открытым кодом на R.
Язык
R — это язык программирования с открытым кодом и среда выполнения, широко используемая математиками и специалистами по статистике и особенно популярная среди ученых и исследователей благодаря своей низкой стоимости. Язык R можно получить бесплатно через сетевой архив Comprehensive R Archive Network (CRAN) по адресу http://CRAN.R-project.org/ на условиях стандартной общедоступной лицензии. R сохраняет все данные, объекты и их определения в памяти и осуществляет управление собственной памятью для обеспечения эффективного использования рабочего пространства. Для работы с языком R, как правило, используется интерфейс командной строки. Однако существуют редакторы и интегрированные среды разработки, например, R Studio.
Популярность R в бизнес-сообществе растет, потому что новые сотрудники, которые работали с R во время учебы, продолжают использовать знакомый инструмент и в трудовой деятельности. Но поскольку R является языком программирования, для проведения прогнозного анализа требуются расширенные навыки работы с технической статистикой и программирования. На рис. 2 показан встроенный графический пользовательский интерфейс R, состоящий из интерактивной области командной строки слева и окна скрипта справа.
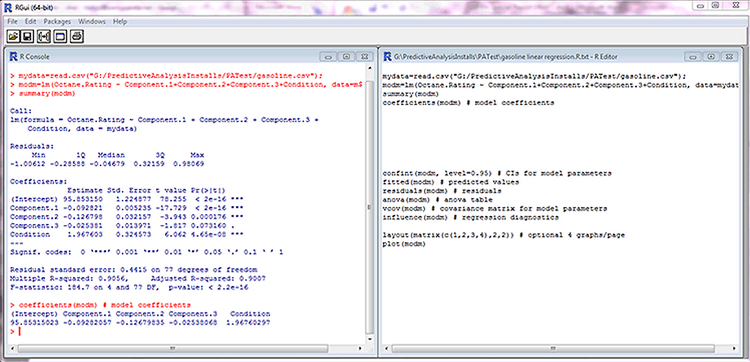
Рис. 2. Графический пользовательский интерфейс для языка R
Основная часть обширных функциональных возможностей прогнозирования R доступна в пакетах, распространяемых через мировую сеть пользователей и разработчиков R в CRAN. Пакеты в CRAN проходят проверку и тестирование перед отправкой, но значительный объем функций тестируется пользователями, а исправления и расширения создаются опытными энтузиастами, а не официальной группой разработки. В результате мы получаем относительно надежный код для широко используемых алгоритмов, но потенциально менее надежный код для малоизвестных алгоритмов. Это обычное дело для программного обеспечения с открытым кодом, разрабатываемого пользователями, официальная поддержка отсутствует.
Основным преимуществом R помимо открытого исходного кода и доступности бесплатно является гибкость этого языка. Поскольку это язык программирования, опытный программист может реализовать на R практически любой алгоритм. В поиске механизма для Expert Analytics компания SAP логичным образом выбрала R. Этот язык не только дополняет архитектуру обработки в оперативной памяти SAP HANA, но также, являясь языком программирования с открытым исходным кодом, никогда не будет приобретен конкурентами, что отрезало бы для SAP доступ к критически важному прогнозному механизму. Поскольку язык R является бесплатным, SAP в соответствии со стоимостью лицензии Expert Analytics должна добавить значительную ценность к доступным алгоритмам на R.
В версии 2.0 Expert Analytics использует 13 алгоритмов на R в обоих режимах SAP HANA, офлайн и онлайн. Алгоритмы на R доступны в режиме офлайн после установки R на локальном компьютере с обязательными пакетами, используемыми Expert Analytics. Алгоритмы на R также применяются для обработки SAP HANA в режиме онлайн. В этом случае R устанавливается на отдельном хосте, который напрямую взаимодействует с сервером SAP HANA. Решение Expert Analytics совместимо с любой версией R 3.1 и выше. Актуальной версией является R 3.1.2.
SAP HANA Predictive Analysis Library (PAL)
SAP HANA PAL — это набор прогнозных алгоритмов в библиотеке функций приложений (AFL) SAP HANA. Он был разработан специально для выполнения в SAP HANA сложных прогнозных алгоритмов, максимально задействуя обработку в базе данных без передачи всех данных на сервер приложений.
Библиотека SAP HANA PAL доступна в любой системе SAP HANA — Service Pack (SP) 05 или выше — после установки AFL. SAP HANA PAL предоставляет функции прогнозирования, которые можно вызвать из кода SQLScript в SAP HANA. В SPS09 (ноябрь 2014 г.) в SAP HANA PAL было доступно 9 категорий алгоритмов (всего 57 алгоритмов, 36 из них прогнозные). В табл. 1 представлено описание девяти категорий.

Табл. 1. Категории алгоритмов в SAP HANA PAL
Оформите подписку sappro и получите полный доступ к материалам SAPPRO
Оформить подпискуУ вас уже есть подписка?
Войти