Партиции и загрузка данных в оперативную память
В данной статье будет рассмотрено, что такое партиции и партиционные таблицы, какие спецификации партицирования существуют, и как произвести загрузку данных в оперативную память в SAP HANA.
Введение
В данной статье будет рассмотрено, что такое партиции и партиционные таблицы, какие спецификации партицирования существуют, и как произвести загрузку данных в оперативную память в SAP HANA.
В связи с тем что существует ограничение на количество строк в таблице — не более 2 млрд., возникает задача преодоления этого ограничения. Задача решается с помощью разбиения таблицы на части, или партицирования. Таким образом, очень большие таблицы могут быть разбиты на маленькие, более управляемые части — партиции. Партиции могут быть распределены между несколькими хостами. Это значит, что запрос к таблице может обрабатываться на нескольких серверах вместо одного, что также способствует дальнейшему распараллеливанию с помощью выполнения нескольких потоков для каждой таблицы.
Партицирование — функция, которая позволяет разбивать большие таблицы на логические части по выбранным критериям, благодаря чему улучшается производительность базы данных.
Партиция — часть таблицы, логически выделенная для удобства хранения и обработки в памяти и состоящая из смежных блоков. Поэтому таблица, которая была разбита на партиции, называется партицированной.
Пример. Имеется таблица с данными кодов операций и сумм, где ключевой столбец — «Дата» (см. рисунок ниже). Представим, что данная таблица содержит много данных, и количество строк подходит к пороговому ограничению 2 млрд. при постоянном увеличении данных. Чтобы избежать переполнения таблицы, разобьем ее на партиции по ключевому полю «Дата», а именно по году. Отметим, что столбец, который используется для разбиения, называется столбцом партиций. В нашем примере будут заданы партиции по годам (2011, 2012, 2013) с помощью следующего SQL-кода (используется функция даты — year ()):
CREATE COLUMN TABLE MY_TABLE (a DATE, b VARCHAR (4), c INT, PRIMARY KEY (a, b)) PARTITION BY RANGE (year (a)) (PARTITION ‘2011’ <= values < ‘2012’, PARTITION ‘2012’ <= values < ‘2013’, PARTITION ‘2013’ <= values < ‘2014’)
В итоге получим следующие партиции (см. Рис.1).
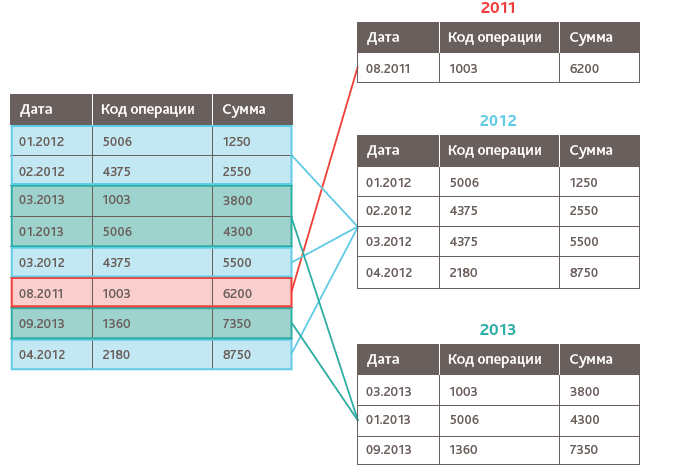
Рис.1
Мы получили три партиции, каждая из которых меньше основной таблицы, т. е. задача с ограничением по количеству строк решена. Отметим, что количество строк в каждой новой партиции также не должно превышать 2 млрд.
Вы можете просмотреть свойства таблицы, вызвав ее контекстное меню и выбрав пункт “Open Definition” (Рис.2). Так, в столбце “Number of Entries”, представленном на рисунке ниже, приведено количество строк, которые были отнесены к каждой из партиций, а столбец “Loaded” показывает статус загрузки в оперативную память (“FULL” — данные полностью загружены в оперативную память).
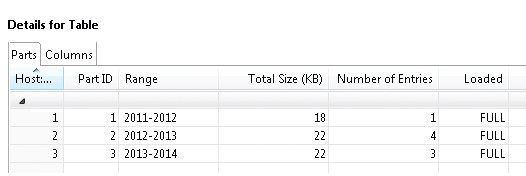
Рис.2
Чтобы просмотреть список всех таблиц и определить, какие из них партицированы, а какие нет, у вас должны быть следующие полномочия: системная привилегия DATA ADMIN и привилегии SELECT и UPDATE для изменения таблицы или схемы. Если привилегии есть, то нужно вызвать контекстное меню папки Catalog, схемы или папки Tables и выбрать пункт “Show Table Distribution”. Отобразится список таблиц (см. Рис.3).
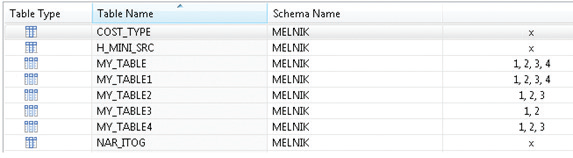
Рис.3
Заметим, что значок в столбце “Table Type” у партицированных и непартицированных таблиц выглядит по-разному. Также непартицированные таблицы отмечены крестиком «×», а для партицированных указаны партиции, на которые они разбиты. В данном окне вы можете разбить непартицированные таблицы или объединить партиции в уже разбитых таблицах с помощью команд из контекстного меню:
- Partition Table — Разбить таблицу на партиции
- Merge Partitions — Объединить партиции
Также для объединения всех частей партицированной таблицы в единую таблицу можно использовать следующий SQL-код:
ALTER TABLE MY_TABLE3 MERGE PARTITIONS;
Результат объединения партиций представлен на Рис.4.
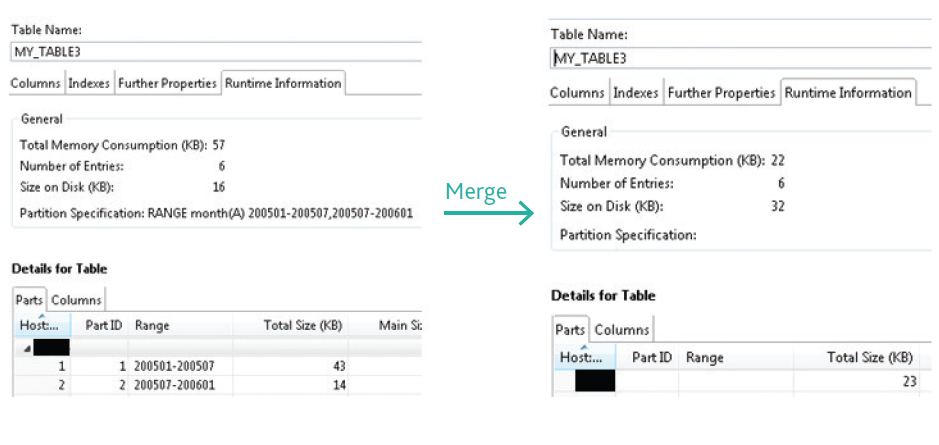
Рис.4
Стоит отметить, что партицирование также важно при распределении таблиц по нескольким хостам SAP HANA, что способствует улучшенному распараллеливанию запросов. Поэтому партицирование обычно используется в распределенных системах, но оно также может быть полезно для систем с одним сервером.
Критерии, в соответствии с которыми таблица разбивается на партиции, называются спецификациями партицирования. В зависимости от использования спецификаций, партицирование бывает одно- и многоуровневым.
Существуют следующие спецификации партицирования:
- Hash
- Round-Robin
- Range
Если в партицировании используется какая-либо одна спецификация, то оно называется одноуровневым. Иначе при использовании вложенных спецификаций мы имеем дело с многоуровневым партицированием.
Одноуровневое партицирование
Hash-партицирование используется для одинакового распределения строк по партициям при распределении нагрузки и преодоления ограничения в 2 млрд. строк. Количество партиций вычисляется с помощью хэш-функции со значением заданного столбца.
Hash-партицирование не требует углубленного знания фактических значений таблицы. Для него должны быть указаны столбцы партиций. Можно использовать несколько таких столбцов. Если таблица имеет первичный ключ, то столбцы партиций должны быть частью первичного ключа. Ниже приведен пример SQL-кода для создания таблицы с помощью Hash-партицирования и четырьмя партициями.
CREATE COLUMN TABLE MY_TABLE (a INT, b INT, c INT, PRIMARY KEY (a, b)) PARTITION BY HASH (a, b) PARTITIONS 4;
С помощью функции GET_NUM_SERVERS, которая получает значение количества серверов, можно не указывать фиксированное количество партиций — оно будет задано динамически во время выполнения в соответствии с конфигурацией. Сколько серверов в системе, столько и будет создано партиций. Рекомендуется задавать количество партиций следующим образом:
PARTITION BY HASH (a, b) PARTITIONS GET_NUM_SERVERS ();
Более подробная информация о SQL-синтаксисе для партицирования содержится в руководстве SAP HANA SQL Reference.
Как же происходит процесс загрузки созданной таблицы в оперативную память? SAP HANA сама управляет загрузкой и выгрузкой таблиц в память и из памяти. Но при необходимости можно загружать и выгружать отдельные таблицы вручную.
Например, при создании таблицы она еще не загружена в память. Это можно проверить, вызвав контекстное меню таблицы, выбрав пункт “Open Definition”, и затем перейти на вкладку “Runtime Information”. На Рис.5 видно, что созданная таблица партицирована, но не загружена в память (статус “Loaded” = NO и “Total Memory Consumption (KB) ” = –).
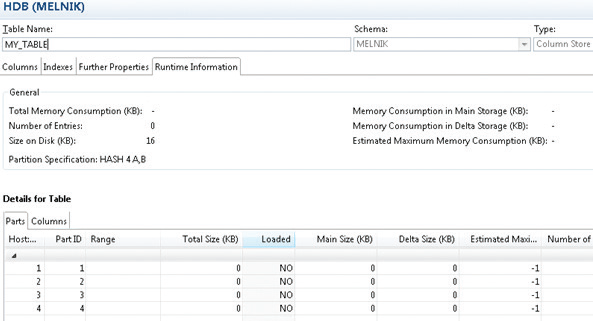
Рис.5
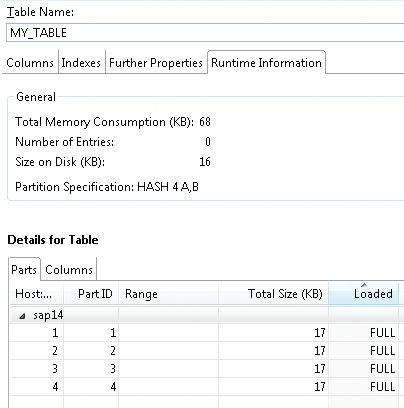
Рис.6
Чтобы загрузить таблицу в оперативную память, достаточно в контекстном меню таблицы выбрать пункт “Open Content”. Также таблица будет загружена в память, если вы добавите в нее данные через INSERT, сделаете запрос SELECT и т. д. На рисунке 6 отображено изменение свойств таблицы после запуска “Open Content”. Мы видим, что таблица была загружена в оперативную память, так как статус “Loaded” = FULL (его начение может быть равно PARTIALLY) и “Total Memory Consumption (KB) ” = 68.
Можно самостоятельно выгрузить и загрузить таблицу в память с помощью команд, которые есть в контекстном меню таблицы:
- Unload — Освободить память, выгрузив таблицу из памяти
- Load — Загрузить таблицу в память
Более подробную информацию о разбиении таблиц можно получить, открыв просмотр M_CS_COLUMNS, в котором содержится информация о том, какие столбцы в каких партициях сколько памяти занимают и т. д.
Например, для таблицы:
CREATE COLUMN TABLE TAB4 (a INT, b INT, c INT, d INT, PRIMARY KEY (a, b)) PARTITION BY RANGE (a) (PARTITION ‘2011’ <= values < ‘2012’, PARTITION ‘2012’ <= values < ‘2013’, PARTITION ‘2013’ <= values < ‘2014’)
Выполним запрос (данные предварительно добавлены в таблицу, и память освобождена):
SELECT a, b FROM ”TAB4” WHERE a=2011
На Рис.7 представлено, как будет произведена загрузка
Если хотите прочитать статью полностью и оставить свои комментарии присоединяйтесь к sapland
ЗарегистрироватьсяУ вас уже есть учетная запись?
Войти
Обсуждения 1
1
Комментарий от
Денис Озорнов
| 09 сентября 2015, 16:47
Что было бы действительно интересно, как мне кажется:
1) сравнение методов партицирования, описание в чем преимущество того или иного метода.
2) Какие плюсы и какие минусы каждого из методов на разных прикладных задачах
3) описание не освещенных в мануалах аспектов, как-то: а) что будет с данными, если разделение на партиции\слияние партиций происходит на таблице с данными, б) сколько уровней секционирования может быть максимально
От себя хочется добавить: не смотря на описание в хелпе (и в статье), что для hash и range секционирования надо что бы в таблице был первичный ключ, SP09 позволял создавать секционирование на таблице даже в его отсутствие.