Ускорение программ через параллельное программирование
Возникают задачи, в которых требуется выполнить большое количество однотипных операций. При этом, тело операций инкапсулировано, а порядок их выполнения не влияет на конечный результат. Суммарное время выполнения операций может достигать нескольких часов. Примерами таких действий может быть: массовое выполнение BAPI или пакетного ввода. Ускорить такие программы можно через параллельное программирование (pRFC).
Оглавление
Код демонстрационной программы Z_PRFC_EXAMPLE
Код функционального модуля Z_TEST_RFC
Введение
Возникают задачи, в которых требуется выполнить большое количество однотипных операций. При этом, тело операций инкапсулировано, а порядок их выполнения не влияет на конечный результат. Суммарное время выполнения операций может достигать нескольких часов. Примерами таких действий может быть: массовое выполнение BAPI или пакетного ввода. Ускорить такие программы можно через параллельное программирование (pRFC).
Данная статья предназначена для тех, кто понимает принципы работы RFC, умеет работать с синхронными (sRFC), асинхронными (aRFC) и транзакционными RFC (tRFC) и хочет научиться работать с параллельными RFC (pRFC).
Если вы сталкиваетесь с RFC впервые или хотите освежить знания, рекомендую предварительно ознакомиться с материалами:
- Статья о видах RFC с примерами их работы
- Справка SAP по синхронным RFC (sRFC)
- Справка SAP по асинхронным RFC (aRFC)
- Справка SAP по транзакционным RFC (tRFC)
Концепция
Параллельный RFC работает схожим с aRFC образом, и вызывается с помощью дополнения DESTINATION IN GROUP <имя_группы_серверов>. Группы серверов pRFC определяют максимально возможные ресурсы для выполнения параллельных задач. Группы настраиваются в RZ12 (Рис. 1). Если в качестве имени группы указать DEFAULT или SPACE, то вызов будет происходить на любой из определенных групп, в зависимости от их загруженности.
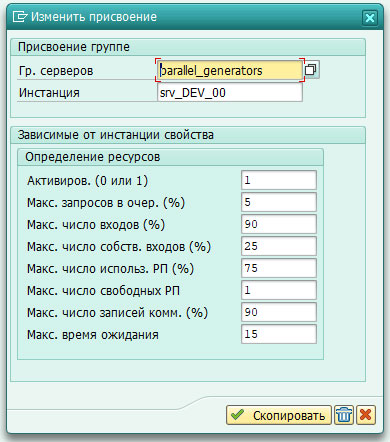
Рис. 1 – Интерфейс настройки группы серверов в RZ12
Для параллельной обработки в SAP реализован набор функциональных моделей, определенных в группе функций SPBT.
Перед распараллеливанием задач необходимо инициализировать группу серверов, в которой будет выполняться параллельная обработка. Группу можно инициализировать через SPBT_INITIALIZE и только один раз. При повторном вызове SPBT_INITIALIZE будет исключение PBT_ENV_ALREADY_INITIALIZED, если группа уже была инициализирована, или CANT_INIT_DIFFERENT_PBT_GROUPS, если ранее была инициализирована другая группа.
Для определения доступности ресурсов определенной группы можно воспользоваться SPBT_INITIALIZE или SPBT_UPDATE_SRV_RESOURCE_INFO. При успешном выполнении ФМ вернут значения MAX_PBT_WPS и FREE_PBT_WPS, в которых содержатся число максимально доступных и свободных процессов на сервере.
Для определения сервера, на котором будет выполняться задача pRFC, необходимо вызывать SPBT_GET_PP_DESTINATION сразу же после запуска pRFC.
Чтобы исключить конкретный сервер из дальнейшего использования для задач параллельной обработки (например, при исключении COMMUNICATION_FAILURE), необходимо использовать ФМ SPBT_DO_NOT_USE_SERVER.
На Рис.2. представлена диаграмма активности pRFC.
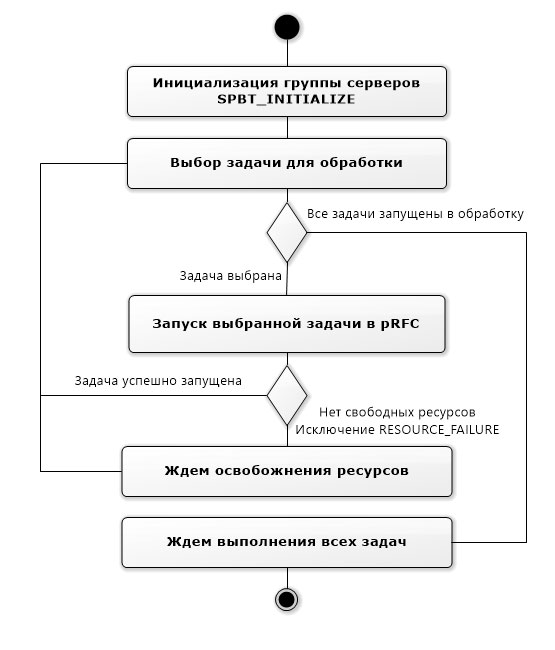
Рис 2. UML диаграмма активности pRFC
Демонстрационный пример
Для демонстрации сделаем тестовую программу и функциональный модуль Z_TEST_RFC. Функциональный модуль будет выполнять какую-нибудь длительную задачу, которую мы будем запускать в параллельном режиме. Пусть это будет возведение числа в квадрат, а для имитации длительной работы сделаем задержку от 3 до 5 секунд.
Допустим, нам нужно выполнить 20 раз данную операцию и возвести первых 20 натуральных чисел в квадрат. На Рис. 3. представлен результат выполнения данной операции при 9-ти свободных процессах. При последовательной обработке на эту же операцию потребовалось бы 80 секунд.
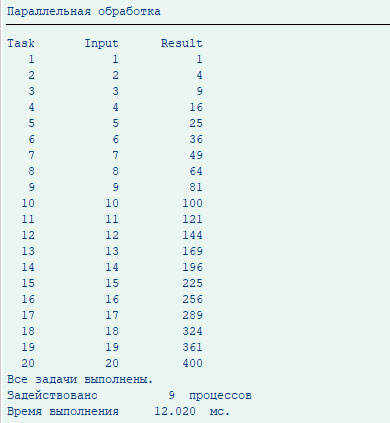
Рис. 3 – Результат работы параллельной обработки
Код демонстрационной программы Z_PRFC_EXAMPLE
REPORT z_prfc_example.
TYPES:
BEGIN OF gts_task,
task TYPE c LENGTH 5,
input TYPE i,
result TYPE i,
END OF gts_task.
DATA gv_tasks TYPE i.
DATA gt_tasks TYPE TABLE OF gts_task.
START-OF-SELECTION.
PERFORM main.
FORM main.
DATA lv_time_start TYPE i.
DATA lv_time_end TYPE i.
DATA lv_time TYPE i.
DATA lv_total TYPE i.
DATA lv_free TYPE i.
FIELD-SYMBOLS <ls_tasks> TYPE gts_task.
CALL FUNCTION
Если хотите прочитать статью полностью и оставить свои комментарии присоединяйтесь к sapland
ЗарегистрироватьсяУ вас уже есть учетная запись?
Войти
Обсуждения 11
11
Комментарий от
Олег Точенюк
| 31 августа 2020, 14:28
Паралельно 3 процесса: 11 520 002 милисекунд
Последовательно : 20 632 688 милисекунд
А ну и сейчас перформы уже не модно Василий К. придет будет говорить, что это не правильное программирование :-), на классах параллельность выглядит чуток интереснее и красивее в реализации, программа обработки выглядит типа так:
LOOP AT <по каким-то объектам которые надо обработать>.
lcl->read( ). "Прочитали что надо обработать в процесе
lcl->process( ). "Запустили процесс обработки
lcl->wait( ). "Ждем если нет свободных процессов, иначе идем на следующий шаг.
ENDLOOP.
Комментарий от
Александр Носов
| 31 августа 2020, 16:47
Олег Точенюк 31 августа 2020, 14:28
Чего-то у меня цифры не бьются. Например на установку статуса пусть уходит 1 секунда, и время закрытия 5 часов итого за это время при последовательном закрытии у тебя закрывается 5 * 3600 = 18 000 заказов. После распараллеливания, заказ как зарывался за 1 секунду так и будет закрываться, что его параллельно, что последовательно грузить (бапишке фиолетово она в своем процессе отработает необходимое ей время как ты ее не крути). По твоим словам, теперь это все стало отрабатывать за пару минут, ну пусть это будет 5 минут для ровности. Итого у тебя каждую минуту закрывается сколько? Правильно 3600 / 5 = 720 заказов. Короче я в своей жизни систему с 720 свободными процессами не видел еще, твоя видимо первая будет, ну это чтобы оно таки за пару, точнее 5 минут отработало. В общем если бы была реальная статистика с рабочей системы приведена, было бы чуть интереснее. В свое время когда такое делал я просто привел цифры, чтение 120 000 документов:
Паралельно 3 процесса: 11 520 002 милисекунд
Последовательно : 20 632 688 милисекунд
А ну и сейчас перформы уже не модно Василий К. придет будет говорить, что это не правильное программирование :-), на классах параллельность выглядит чуток интереснее и красивее в реализации, программа обработки выглядит типа так:
LOOP AT <по каким-то объектам которые надо обработать>.
lcl->read( ). "Прочитали что надо обработать в процесе
lcl->process( ). "Запустили процесс обработки
lcl->wait( ). "Ждем если нет свободных процессов, иначе идем на следующий шаг.
ENDLOOP.
Комментарий от
Олег Точенюк
| 01 сентября 2020, 07:47
Александр Носов 31 августа 2020, 16:47
Если 5-8 часов разделить на 30-40 свободных процессов, получится 7-16 минут.
Комментарий от
Александр Носов
| 01 сентября 2020, 08:18
Олег Точенюк 01 сентября 2020, 07:47
Хорошая у вас система, с сорока свободными процессами и еще наверное плюс десятком дополнительных, на других пользователей, пока программа выполняется :-)
Комментарий от
Олег Точенюк
| 01 сентября 2020, 09:42
Александр Носов 01 сентября 2020, 08:18
Ограничение группы серверов не более 25% от общего количества процессов. Всего более 100 процессов. Это разве много?
Комментарий от
Александр Носов
| 01 сентября 2020, 10:09
Олег Точенюк 01 сентября 2020, 09:42
Диалогов? 100 процессов не попадалось если честно, обычно гораздо скромнее. Кстати это какое количество пользователей у вас в системе, если не секрет, что более 100 диалогов открыто?
Насчет пользователей не располагаю достоверной информацией.
Комментарий от
Олег Точенюк
| 02 сентября 2020, 12:19
Александр Носов 01 сентября 2020, 10:09
Да, диалогов. А у вас какие значения вернет SPBT_INITIALIZE в продуктиве?
Насчет пользователей не располагаю достоверной информацией.
MAX_PBT_WPS = 24
FREE_PBT_WPS = 22 (на момент запуска)
Пользователей скажем так где-то 1100-1200, понятно что активных гораздо меньше. Система S/4
Комментарий от
Александр Носов
| 03 сентября 2020, 07:30
Олег Точенюк 02 сентября 2020, 12:19
Ну например так:
MAX_PBT_WPS = 24
FREE_PBT_WPS = 22 (на момент запуска)
Пользователей скажем так где-то 1100-1200, понятно что активных гораздо меньше. Система S/4
Комментарий от
Олег Точенюк
| 03 сентября 2020, 08:04
Александр Носов 03 сентября 2020, 07:30
Даже если использовать треть диалогов для параллельных задач, можно в 8 раз ускорить некоторые процессы. Для некоторых операций это будет серьезным увеличением.
Комментарий от
Виталий Глущенко
| 01 октября 2020, 00:16
Олег Точенюк 31 августа 2020, 14:28
Чего-то у меня цифры не бьются. Например на установку статуса пусть уходит 1 секунда, и время закрытия 5 часов итого за это время при последовательном закрытии у тебя закрывается 5 * 3600 = 18 000 заказов. После распараллеливания, заказ как зарывался за 1 секунду так и будет закрываться, что его параллельно, что последовательно грузить (бапишке фиолетово она в своем процессе отработает необходимое ей время как ты ее не крути). По твоим словам, теперь это все стало отрабатывать за пару минут, ну пусть это будет 5 минут для ровности. Итого у тебя каждую минуту закрывается сколько? Правильно 3600 / 5 = 720 заказов. Короче я в своей жизни систему с 720 свободными процессами не видел еще, твоя видимо первая будет, ну это чтобы оно таки за пару, точнее 5 минут отработало. В общем если бы была реальная статистика с рабочей системы приведена, было бы чуть интереснее. В свое время когда такое делал я просто привел цифры, чтение 120 000 документов:
Паралельно 3 процесса: 11 520 002 милисекунд
Последовательно : 20 632 688 милисекунд
А ну и сейчас перформы уже не модно Василий К. придет будет говорить, что это не правильное программирование :-), на классах параллельность выглядит чуток интереснее и красивее в реализации, программа обработки выглядит типа так:
LOOP AT <по каким-то объектам которые надо обработать>.
lcl->read( ). "Прочитали что надо обработать в процесе
lcl->process( ). "Запустили процесс обработки
lcl->wait( ). "Ждем если нет свободных процессов, иначе идем на следующий шаг.
ENDLOOP.
Пример в статье идеальный, 20 задач, 9 параллельных процессов, задача грузит только CPU, поэтому отлично подходит для параллезации. Получили шикарный прирост производительности 80/12 ~= 6,7 раз. Реальный пример, от Олега дает всего лишь 20 632 688/11 520 002 ~1,79 увеличение, при 3-х кратной парализации.
Лучше вначале разобраться, где у вас узкое место и почему оно именно настолько узкое. Иначе есть риск наткнуться на "бо-бо" в продуктивной системе, после "новаторской" оптимизации.
Комментарий от
Олег Точенюк
| 01 октября 2020, 09:30
Виталий Глущенко 01 октября 2020, 00:16
все ж было б неплохо указать в статье, что не стоит параллелить пока не выжали все из последовательной обработки. А то находятся последователи индуских талмудов, так напараллелят, что другие процессы стоят.
Пример в статье идеальный, 20 задач, 9 параллельных процессов, задача грузит только CPU, поэтому отлично подходит для параллезации. Получили шикарный прирост производительности 80/12 ~= 6,7 раз. Реальный пример, от Олега дает всего лишь 20 632 688/11 520 002 ~1,79 увеличение, при 3-х кратной парализации.
Лучше вначале разобраться, где у вас узкое место и почему оно именно настолько узкое. Иначе есть риск наткнуться на "бо-бо" в продуктивной системе, после "новаторской" оптимизации.