Введение в High Availability SAP HANA
В настоящей статье освещаются технологические подходы, используемые в SAP HANA для реализации процесса аварийного восстановления данных.
ГОСТ Р 53647.2-2009 определяет непрерывность бизнеса (business continuity) как «стратегическую и тактическую способность организации планировать свою работу в случае инцидентов и нарушения её деятельности, …. непрерывность деловых операций на установленном приемлемом уровне.»
Непрерывность бизнеса обеспечивается при наличии достаточно быстрых и эффективных средств восстановления данных и работоспособности информационных систем. В настоящей статье освещаются технологические подходы, используемые в SAP HANA для реализации процесса аварийного восстановления данных.
1. Введение в High Availability SAP HANA
1.1. Восстановление – ключевые показатели
В качестве ключевых показателей эффективности восстановления используются показатели Recovery Period Objective (RPO) и Recovery Time Objective (RTO).
RPO является максимально допустимым периодом, в течение которого данные могут быть потеряны без возможности восстановления (время между созданием последней резервной копии и аварией), RTO представляет собой максимально допустимое время, необходимое для восстановления системы.
Как in-memory СУБД, HANA должна не только обеспечивать надежность данных в случае сбоев системы и быстрое восстановление данных (в памяти).
На Рис. 1 показаны фазы высокой готовности HANA.
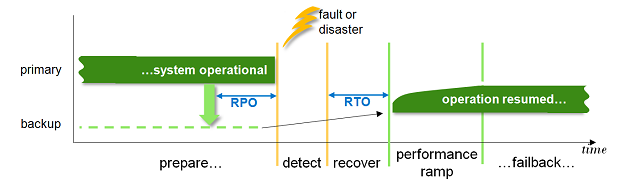
Рис.1 Фазы высокой готовности HANA
Перая фаза (prepare) – это готовность к неизбежному сбою. В этот период основная система работает, данные резервируются, и резервная система готова в случае сбоя принять управление инфраструктурой. Вторая фаза – обнаружение сбоя. Сбой фиксируется либо автоматически, либо административно (во избежание ложных автоматических срабатываний), после фиксации будет приведен в действие процесс восстановления(третья фаза) . В результате работоспособность основной системы будет восстановлена.
Для чувствительных к сбою систем требуется обеспечить RPO с нулевой потерей данных в случае локальных сбоев, и зачастую даже в случае системных аварий. Однако проблемы аварийного восстановления (Disaster Recovery) отличаются от проблем восстановления при локальных сбоях и, в этом случае, для достижения нулевого RPO и минимального RTO, данные должны быть синхронизированы в рамках сложных распределенных ланшафтов, что может потребовать выполнения специальных требований к организации отказоустойчивых вычислительных архитектур
В SAP HANA организовано три уровня поддержки аварийного восстановления и две автоматические функции поддержки.
1.2 Уровень певрый. Резервное копирование (Backups)
SAP HANA, как технология энергозависимой памяти, полностью сохраняет любые транзакции, изменяющие данные, такие как вставки, удаления и обновления. Таким образом, работа системы может быть восстановлена без потери данных даже после отключения электроэнергии. SAP HANA сохраняет два типа данных:
- журнальные файлы транзакций (redo logs),
- изменения данных, используя контрольные точки сохранения (savepoints).
Журналы используются для записи изменений. Для обеспечения восстановления тразакции нет необходимости сохранять ее результаты в момент фиксации ее завершения (при выполнении commit), достаточно сохранить журнал. После сбоя, наиболее актуальное состояние БД может быть восстановлено путем применения (наката) журнала, перевыполнив завершенные транзакции и откатив незавершенные.
Одним из преимуществ использования контрольных точек является скорость при перезапуске БД: при запуске системы журналы не прочитываются целиком с самого начала, только с самой последней контрольной точки. По умолчанию контрольные точки выполняются каждые 5 минут, однако этот период может быть гибкно настроен админстратором.
Более новые контрольные точки перезаписывают старые, при этом существует возможность «заморозить» любую контрольную точку для дальнейшего использования, и создать снимок данных (snapshot). Снимки могут быть воспроизведены в виде полных резервных копий БД, котороые могут быть ипользованы для восстановления БД на определнный момент времени. В дополнение к этому сокращение периодов резервирования журналов обеспечивает возможность восстановления после фатальных сбоев с минимальными потерями данных.
На Рис. 2 показаны контрольные точки, сохраненные в локальном дисковом хранилище, и дополнительные резервные копии, сохраненные в резервном хранилище. Локальное восстановление после сбоя использует последнюю контрольную точку, а затем применяет последние журналы, для восстановления базы данных без потери данных. Если локальное хранилище было повреждено, все еще возможно восстановить БД из резервной копии данных (или последнего снимка), и резервных копий журналов, но уже с некоторой потерей данных.
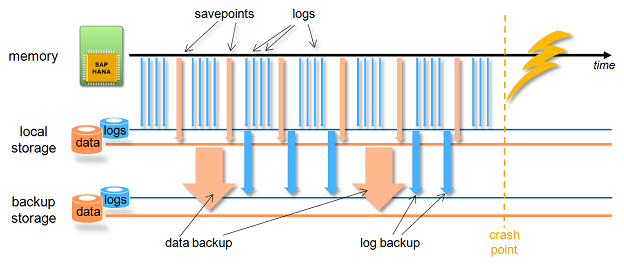
Рис. 2 Контрольные точки сохранения
Регулярная запись резервных копий в удаленное хранилище является простым и относительно недорогим способом подготовиться к непредвиденному сбою (см. Рис.3). Однако, в зависимости от выбранного метода резервировования, фактический RPO может варьироваться от часов до нескольких дней.
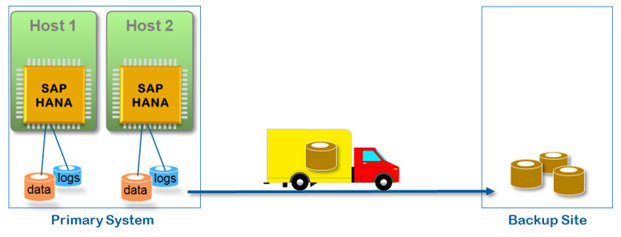
Рис. 3 Резервное копирование БД в удаленное хранилище
1.3. Уровень второй. Репликация хранения (Storage Replication)
Одиним из недостатков резервных копий БД является потенциальная потеря данных с момента создания последней резервной копии до момента сбоя. Предпочтительным решением, в этом случае, является возможность обеспечить непрерывную репликацию всех сохраненных данных. Аппаратные партнеры SAP предлагают решения для репликации данных, обеспечивая резервное копирование на уровне файловой системы с использованием удаленной сетевой системы хранения (более подробно о предлождении аппаратных партнеров SAP в цикле вебинаров SAP HANA Online). В этом случае транзакция SAP HANA завершается только тогда, когда локально сохраненный журнал транзакций будет реплицирован в уделнное хранилище. Такой подход называется синхронная репликация (synchronous storage replication). Синхронная репликация может эффективно использоваться при условии, что расстояние между основной и резервной БД составляет до 100 километров (см. Рис.4).
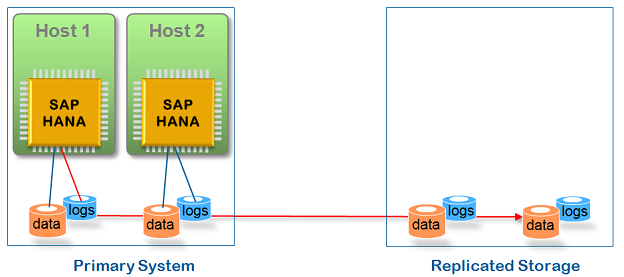
Рис. 4 Синхронная репликация в SAP HANA
Благодаря поддержке непрерывности, репликация поддерживает более приемлимый уровень RPO, чем резервное копировие, однако при для реализации этого подхода требуются надежные каналы с высокой пропускной способностью и низкими задержками передачи между основной и резервной сторной.
В случае сбоя, администратор переподключает систему к резервному хранилищу и перезапускает HANA.
1.4. Уровень третий. Системная репликация (System Replication)
Системная репликация – это алтьтернатива High Availability решениям, обеспечивающая наиболее короткий RTO, и совместимая с решениями всех аппартных партнеров SAP. Эта репликация использует подход N+N, с использованием резервной системы, состоящей из того же числа узлов, что и основная система. Каждая служба и экземпляр основной системы HANA работают синхронно со службой и экземпляром резервной системы (см. Рис.5).
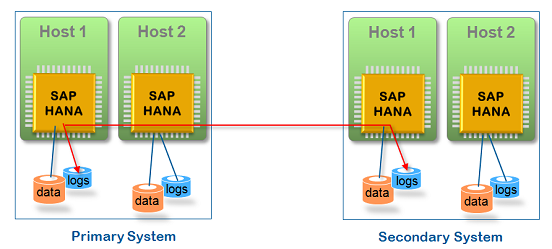
Рис. 5 Системная репликация в SAP HANA
Резервная система может быть расположена рядом с основной, чтобы поддерживать отказоустойчивую конфигурацию при плановых простоях или отработки управления локальными сбоями. Альтернативно или в дополнение резервная система может быть расположена удалённо для целей аваррийного восстановления. Как и репликация хранения эта возможность аварийного восстановления требует надежного сетевого соединения между основной и резервной системами.
Экземпляры резервной системы работают в режиме «живой репликации» (live replication mode). В этом режиме все службы резервной системы постоянно синхронизируются со службами основной системы, включая репликацию и сохранение данных и журналов транзакций, а также загрузку данных в память. В этом режиме резервная система не обрабатывает запросы.
В альтернативной конфигурации, называемой репликацией без предварительной загрузки (replication without data-preload), резервная система не загружает данные в память, соответсвенно, использует сранительно небольшой объем ресурсов оперативной памяти. Это позволяет резервной системе использоваться в качестве тестового контура или контура разработки. При этом RTO в случае отказа в такой конфигурации, разумеется, будет больше.
Как работает системная репликация? В режиме живой репликации каждый копонент службы устанавливает соединение со службой рабочей системы и запрашивает снимок данных. После этого журналы транзакций после сохранения в основной системе копируются в резервную систему. Транзакция в основной системе считается не заврешенной, до тех пор пока, журналы транзакций не реплицированы в резервную систему.
Поддерживаются следющие режимы системной репликации:
- Синхронная. Основная система ожидает завершения тразакции, пока не получит ответ, что журнал сохранился в резервной системе. Этот режим гарантирует немедленную согласованность между обеими системами.
- Синхронная в памяти. Основная система фиксирует
Если хотите прочитать статью полностью и оставить свои комментарии присоединяйтесь к sapland
ЗарегистрироватьсяУ вас уже есть учетная запись?
Войти