Параллельные вычисления в SAP HANA 73
За последний десяток лет значительно повысилась производительность процессоров: увеличилась тактовая частота, количество ядер на один процессор. Только на одном современном сервере может быть установлено от 16 до 64 многоядерных процессоров, от 2 до 12 ядер в каждом. Использование многоядерной архитектуры вместе с возможностями параллельных вычислений позволяет решать задачи, недоступные еще десять лет назад.
Введение
За последний десяток лет значительно повысилась производительность процессоров: увеличилась тактовая частота, количество ядер на один процессор. Только на одном современном сервере может быть установлено от 16 до 64 многоядерных процессоров, от 2 до 12 ядер в каждом. Использование многоядерной архитектуры вместе с возможностями параллельных вычислений позволяет решать задачи, недоступные еще десять лет назад.
Параллельная обработка данных
Платформа SAP HANA позволяет реализовать возможности быстрой обработки данных за счет распараллеливания процессов и хранения данных в соответствии с технологией in-memory.
Традиционно данные в СУБД хранятся в построчном виде, то есть кортежи хранятся в памяти последовательно. Альтернативой такому подходу является хранение данных по столбцам, то есть значения каждого из столбцов в памяти будут идти друг за другом. Наглядно принцип хранения данных по столбцам представлен на Рис.1.
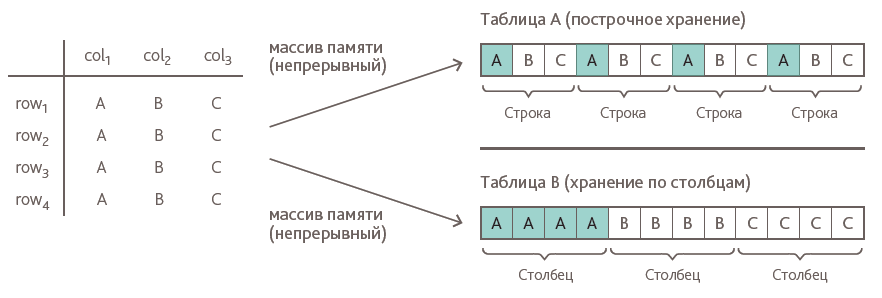
Рис.1. Способы хранения табличных данных
Как показывают исследования [2], одной из наиболее частых операций с БД в корпоративной среде является чтение множеств данных. Технология in-memory позволяет хранить данные как по строкам, так и по столбцам. Хранение данных по столбцам в SAP HANA дает возможность выполнять подобные операции более эффективно, чем при построчном хранении.
Благодаря хранению данных в ОЗУ и кэше процессора время обращения к данным ускоряется на порядки по сравнению со временем доступа к жестким дискам (HDD) и твердотельным накопителям (SSD).
На Рис.2 указано время обращения к носителю информации (жесткий диск, флэш-память, ОЗУ, кэш 3-го уровня, кэш 2-го уровня, кэш 1-го уровня) для двухъядерного процессора с тактовой частотой 2 Ghz.

Рис.2. Сравнение скорости доступа
Из Рис.2 видно, что обращение к ОЗУ быстрее, чем к жесткому диску, в 100 000 раз. При сравнении же оперативной памяти с памятью процессора видно, что наибольший выигрыш в отношении скорости доступа к данным показывает кэш 1-го уровня — он быстрее в 200 раз [4].
SAP HANA использует параллелизм в рамках комплекса блейд-серверов и в части ядер отдельного процессора. Поскольку SAP HANA предусматривает организацию оборудования в виде стойки блейд-серверов, система позволяет разделять данные по серверам в соответствии со схемами секционирования. Вторым аспектом является параллельная обработка данных в рамках одного сервера — многоядерный параллелизм с доступом к общей памяти. Главная цель подхода состоит в оптимизации доступа к общей памяти и максимальной локализации данных в кэше процессора.
Большое количество ядер позволяет нагрузить каждое ядро «его собственными» процессами.
Возможность параллельно выполнять вычисления также обеспечивается за счет принципа SIMD (Single Instruction Multiple Data). Традиционно вычисления в процессоре выполняются в скалярном виде: одна инструкция возвращает один результат. Для SIMD-вычислений необходимы специальные инструкции процессора Intel SSE2/SSE3/ SSE4, которые позволяют за одну команду получить набор значений.
Скалярные вычисления
- Используются стандартные инструкции процессора
- Одна операция выдает один результат
Векторные вычисления
- Используются инструкции Intel SSE2/SSE3/SSE4
- Одна операция выдает вектор значений
Стоит отметить, что SIMD-вычисления оптимально подходят для БД HANA. При организации данных по столбцам каждую колонку таблицы можно представить в виде массива. В памяти данные массива лежат последовательно, что позволяет SIMD-инструкциям вычислять сразу несколько значений за одну команду.
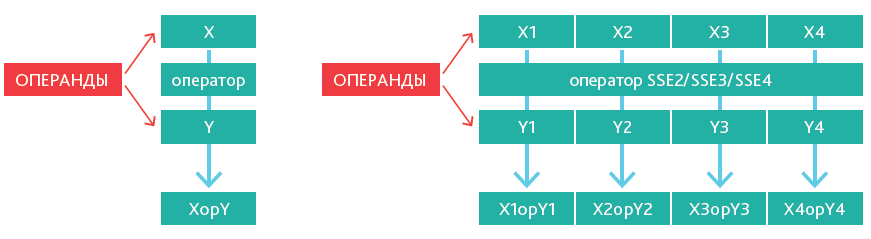
Рис.3. Сравнение методов вычислений в рамках одного процессора
Рассмотрим распараллеливание вычислений на примере вызова процедуры. Демонстрационная процедура принимает на вход две таблицы, две другие — возвращает.
На Рис.4 представлена схема выполнения запроса. Как видно из схемы, при вызове процедуры HANA разделяет выборку данных на два потока, по одному на каждую таблицу. После завершения выборки результаты в отдельных потоках объединяются — с получением двух результирующих таблиц.
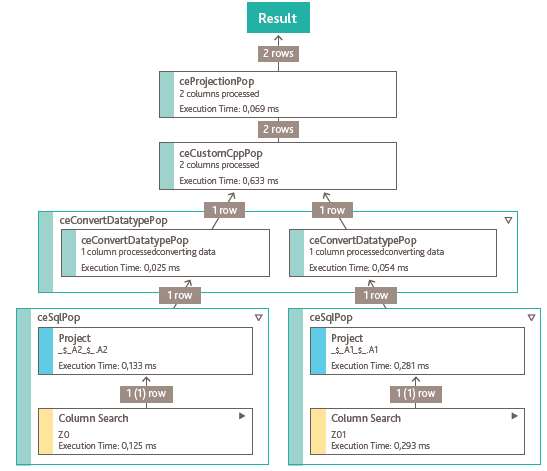
Рис.4.
Если хотите прочитать статью полностью и оставить свои комментарии присоединяйтесь к sapland
ЗарегистрироватьсяУ вас уже есть учетная запись?
Войти

Обсуждения 1
1
Комментарий от
Виталий Глущенко
| 15 августа 2015, 20:23
А вот дальше появились вопросы. Предполагаю, что просто опущены некоторые детали, которых мне не хватило.
Например, в начале написано "Предположим, для выполнения задачи используется процессор с четырьмя потоками (threads).", а дальше описывается схема в которой активны только 2 потока. Предполагаю, что программно, это может обрабатываться и 4 потоками, когда 2 работают, 2 ждут, но зачем для этого процессор с 4-мя потоками, если достаточно 2-х?
И подскажите, а чем отличается обработка Scan, Aggregation и Join в SAP HANA от аналогичных операций в Oracle?