Расширение стандартного функционала SAP HANA недокументированными разработчиками функциями
Благодаря некоторым недокументированным возможностям можно строить более оптимальные модели. Упростить код. Получить максимальный эффект от использования HANA. Данные возможности распространяются на все построенные модели.
Введение.
Если Вы читаете эту статью, то, скорей всего, уже пробовали формировать модели в HANA или, по крайне мере, собираетесь. Если у Вас есть практический опыт работы с HANA, то Вы, скорей всего, уже видели примеры впечатляющей производительности. Но иногда прирост скорости не столь очевиден. Но вина ли HANA в этом? Скорей всего – НЕТ. Разница во времени выполнения запроса, при использовании разных движков может существенно отличаться. И естественно, Вы знаете, что использовать CE_* функции гораздо выгоднее для увеличения производительности (в подавляющем большинстве). Но всегда ли это возможно? Однозначный ответ – НЕТ! Нужна сортировка – всё, придется использовать стандартный SQL-92.На CE_*-шках её нет. И т.д. Но не расстраивайтесь раньше времени. Кое-что всё-таки есть.
Функция «CE_CALC»
Начнём с самой необходимой (на мой взгляд) функции - CE_CALC. Без этой функции, ну, просто никуда. Ведь всё время необходимо что-то рассчитывать, использовать сложную фильтрацию и т.д., а чаще всего простым делением и умножением дело не ограничивается. Тут – то консультант и начинает «шерстить» документацию, вспоминать что же ещё есть, надеясь отыскать заветную функцию, позволяющую решить его проблему. В стандартной документации описаны следующие функции(по разделаем):
- Conversion Functions (6 функций в описании CE_CALC) а в графическом варианте их 13
- String Functions (14) - 13
- Mathematical Functions (15) - 4
- Date Functions (5) - 10
- Further Functions (4)- 4
Но даже там, где их 4- 4 они всё равно отличаются 
Итак, рассмотрим подробнее, что это за расширенный графический вариант и зачем он нам нужен. Почему его можно использовать и т.д.
Функция CE_CALC используется при создании Calculation View(в дальнейшем просто CV) в виде скрипта. Используется как поле в другой функции - CE_PROJECTION. Это основной вариант. Но при создании CV в графическом виде в PROJECTION-е есть возможность создавать Calculated columns
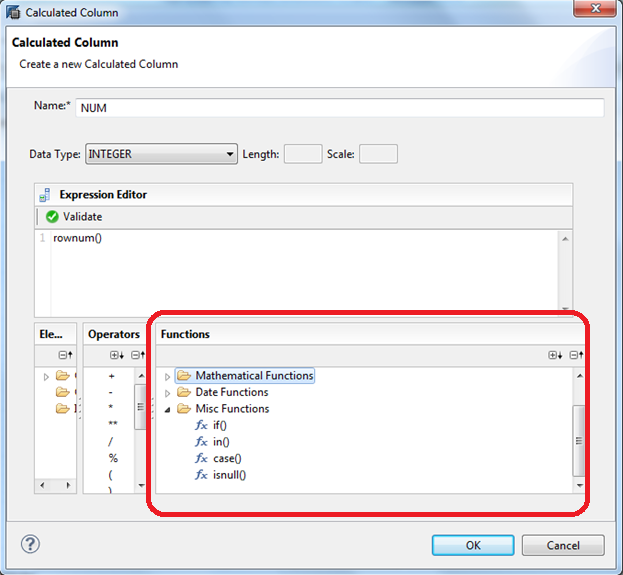
И тут мы видим набор функций:
Если хотите прочитать статью полностью и оставить свои комментарии присоединяйтесь к sapland
ЗарегистрироватьсяУ вас уже есть учетная запись?
Войти
Обсуждения 2
2
Комментарий от
Дмитрий Буслов
| 08 июля 2013, 16:30
Комментарий от
Евгений Селезнёв
| 09 августа 2013, 10:42
A:Why does a mixture of Calculation Engine (CE) functions and pure SQL functions in one stored procedure results in bad performance?
R:The database has to go back and forth between the engines.
по этой причине?