Оперативная память в Linux: особенности управления и мониторинг
Те, кто читает мой блог на постоянной основе, знают, что я очень люблю операционные системы Unix за их изящность, простоту и надёжность. Но время не стоит на месте и надо признать, что HP-UX на данный момент утратила свои позиции и всё больше и больше серверов (причём не только HP) передают под управление операционной системы Linux.
В начале моей карьеры судьба свела меня с коммерческой реализацией операционной системы Unix от компании Hewlett Packard - HP-UX. Очень долго и плотно я работал с данной операционной системой.

Если вернуться к моей скромной персоне, то у меня тенденция идентичная - HP-UX уходит, а Linux в моей работе становится всё больше. Не смотря на то, что операционная система Linux основана на Unix концепции и, по большому счёту, удовлетворяет стандарту POSIX, она, как и любая другая реализация Unix, имеет свои особенности. Сегодня попробуем разобраться с управлением памятью в Linux.
Основную мысль, которую я усвоил, разбираясь в этом вопросе - Linux всегда использует всю оперативную память, которая есть у сервера. Поэтому не так просто ответить на вопрос: хватает ли серверу памяти и каким запасом по ней он обладает? Но обо всём по порядку.
На уровне командной строки существует три команды, которые помогут нам посмотреть информацию по оперативной памяти сервера:
- top
- free
- cat /proc/meminfo
Команда top служит для вывода информации по текущей загрузке сервера, отображая работающие процессы, использование ими ресурсов процессора и памяти сервера. Нас в контексте использования оперативной памяти интересуют 2 строки в шапке вывода команды (рис. 1).
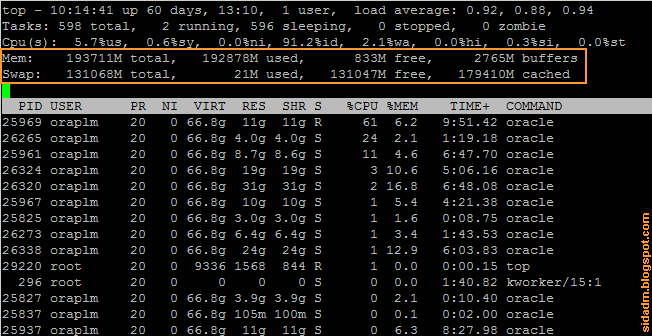 |
| Рис. 1. Пример вывода команды top на сервере с Linux. |
Из вывода мы видим, что всего операционная система видит 193 711 Мб физической памяти, из них только 833 Мб свободно. При этом настроено 131 068 Мб в области подкачки (swap) и почти вся она свободна. По информации от одной этой команды можно сделать преждевременные выводы:
- процессы сервера используют почти всю память,
- но при этом (и это хорошая новость) область подкачки не используется,
- значит оперативной памяти хватает, но запаса нет.
Выводы верны и не верны одновременно. Если увеличить общий объём физической памяти на сервере, то запустив систему, в команде top опять увидим похожую картину.
Если смотреть по отдельным процессам, то в этой команде для нас представляют интерес следующие столбцы:
- VIRT (virtual size of a process) - общий объем используемой памяти: индивидуальная память процесса плюс память, разделяемая с другими процессами, плюс файлы на диске, которые отображаются в память, плюс библиотеки и так далее. Можно сказать, что это максимально доступный процессу объём памяти,
- RES (resident size) - указывает точно сколько в действительности потребляет процесс реальной физической памяти (совпадает со значением в колонке %MEM),
- SHR (shared) - определяет размер разделяемой памяти.
В случае с процессами Oracle в моём примере (рис. 1) в поле VIRT отображается вся память, выделенная на буферы СУБД (SGA) (рис. 2).
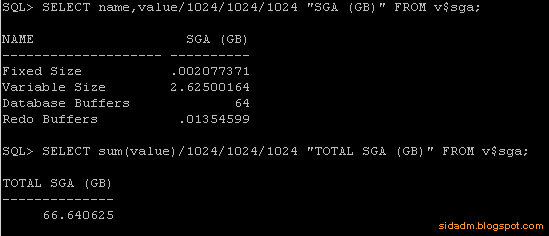 |
| Рис. 2. Размер SGA области текущего экземпляра Oracle. |
Двигаемся дальше. Следующая команда free - служит для вывода информации об использовании оперативной памяти сервера, опять же, с областью подкачки (swap) (рис. 3).
 |
| Рис. 3. Пример вывода команды free на сервере с Linux. |
По умолчанию, команда выводит информацию в килобайтах, для вывода в байтах или мегабайтах можно использовать соответствующие ключи -b и -m (рис. 4).
 |
| Рис. 4. Пример вывода команды free в мегабайтах на сервере с Linux. |
Теперь значения полностью совпадают с выводом команды top, но мы получили немного больше информации. Во-первых, появился ещё один столбец "cached", в котором отображается 179 187 Мб памяти. А во-вторых, поле "-/+ buffers/cache" указывает сколько реально памяти сейчас используют приложения (11 068 Мб) и сколько им ещё может быть выделено системой (182 642 Мб).
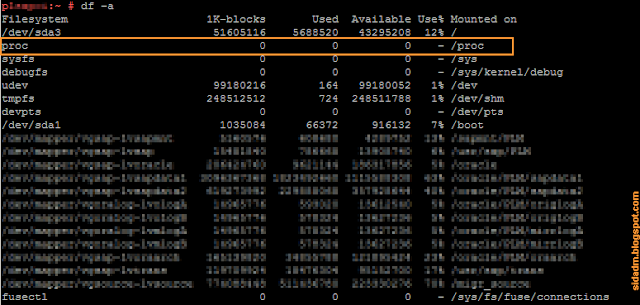
Обе вышеописанные команды используют информацию из файла meminfo, который хранится в псевдо (dummy) файловой системе /proc. Данная файловая система не существует на самом деле, а предоставляет интерфейс к структурам данных в ядре Linux. Найти её можно в выводе команды df -a (рис. 5).
 |
Если хотите прочитать статью полностью и оставить свои комментарии присоединяйтесь к sapland
ЗарегистрироватьсяУ вас уже есть учетная запись?
Войти