Общие аспекты создания интегрированных приложений по обработке данных в реальном времени
Введение
Текущее состояние функциональной среды человеческой деятельности характеризуется стремительным ростом объема цифровых данных. Исследования под названием «Цифровая вселенная», проводимые компанией EMC, показали, что объем цифровых данных удваивается каждые два года. По прогнозам, к 2020 году мировой объем информации увеличится до 44 трлн. Гб. Сегодня каждое домохозяйство ежегодно создает объем данных, достаточный для заполнения хранилища объемом 2 Тб, к 2020 году для хранения создаваемого объема информации потребуется уже 10 Тб. Во многом этому способствует стремительное распространение «Интернета вещей», который в отличие от обычного Интернета характеризуется массовым подключением к Интернету различных устройств, которые в настоящее время используются больше для сбора информации, но уже в ближайшем будущем эти устройства (например, машины) смогут обмениваться информацией и между собой. Согласно исследованиям количество устройств и предметов, которые можно подключить к Интернету, приближается на планете к 200 млрд. единиц, из которых 7% (14 млрд) уже подключены к мировой сети и активно передают информацию. Сейчас данные с таких устройств составляют 2% от суммарного объема информации, генерируемого в мире. По прогнозу специалистов IDC количество подключенных к Сети устройств к 2020 году составит до 32 млрд. штук, что будет соответствовать 10% общего объема генерируемых данных.
Результатом происходящих процессов станет появление колоссальных объемов информации, которые принято объединять под универсальным названием «большие данные» (англ. Big Data). Однако сами по себе эти потоки информации без соответствующей обработки за максимально сжатое время не представляют значительного практического интереса, в частности для бизнеса. Вместе с тем, существующие системы управления базами данных (СУБД), бизнес-приложения и аналитические системы на их основе перестают обеспечивать адекватное управление бизнес-процессами или снижают эффективность ведения бизнеса.
Логичным выходом из сложившейся ситуации является проектирование и разработка систем управления, функционирующих в реальном времени. Основными характеристиками таких систем являются возможность сбора (автоматически или другими способами) любых необходимых данных в реальном времени и их обработка в максимально короткий сроки (идеально — в реальном времени), т. е. задержка между фактом регистрации данных в системе и возможностью сформировать по этим данным определенный результат должна быть минимизирована.
При построении подобных систем управления наиболее перспективным представляется использование новых технологий сбора и обработки информации, основными среди которых, на наш взгляд, являются технология In-memory (обработка данных в оперативной памяти) и RFID-технология (технология радиочастотной идентификации объектов).
«Интернет вещей»
Сам термин «Интернет вещей» (англ. Internet of Things) предложен достаточно давно: по данным Википедии [1] рождение концепции «Интернета вещей» произошло в 1999 году. «Интернет вещей» стал развитием существующей модели Интернета, которая в некотором роде является «Интернетом людей». Из простого сравнения этих двух определений можно легко сделать вывод о том, что «Интернет вещей» будет представлять собой процесс тотального вовлечения в мировую сеть различных устройств (сенсоров, датчиков, контроллеров и т. д.).
Показательным примером таких устройств являются RFID-метки, которые, с одной стороны, характеризуются возможностью массового применения (в силу низкой стоимости, широких возможностей монтажа, простоты использования и др.), а с другой — представляют собой многофункциональное радиоэлектронное устройство (прием и передача данных по радиосигналу, обработка и хранение данных). Следующее поколение RFID-меток, как предполагается, будет обладать уже более широким спектром функциональных характеристик, которые помимо перечисленных выше свойств получат возможность самостоятельно собирать различные данные (например, физические — температура, давление и т. д.).
С другой стороны, появление «Интернета вещей» требует реализации и продвижения новых, согласованных на международном уровне правил передачи данных через Интернет. В этом направлении показательна работа над продвижением стандарта IPv6 для Интернета следующего поколения, которая ведется в Германии — здесь функционирует совет IPv6, который включает в себя HPI (Hasso Plattner Institute — институт Хассо Платтнера), работающий совместно с партнерами от бизнеса, науки и политики. Необходимо отметить, что новый стандарт IPv6 критически важен для развития «Интернета вещей», который позволит устройствам взаимодействовать между собой в сенсорных сетях, например с применением RFID-технологий. Разработанный более десяти лет назад, коммуникационный протокол IPv6 сегодня готов к широкому внедрению и находит активное применение в США и Азии. Новый стандарт не только ключ к интеллектуальным решениям для домашних сетей, но также открывает горизонты для развития новых бизнес-сфер, например, телемедицины, дистанционного управления различными процессами и т. д.
Другим ключевым фактором, серьезно способствующим стремительному распространению «Интернета вещей» и более интенсивному использованию больших данных, является широкое применение и устойчивое развитие технологии in-memory и приложений, построенных на ее основе.
Большие данные
Согласно Википедии [2], большие данные — массив наборов данных, столь значительный и сложный, что его становится трудно обрабатывать, используя классические СУБД или традиционные приложения. Типовыми функциями обработки данных здесь являются захват данных, трансформация, хранение, параллельный допуск, анализ, визуализация и др. По определению компании Gartner, большие данные — это объемные, вариативные, «быстрые» информационные активы, которые требуют новых форм обработки для улучшения качества принимаемых решений, открытия новых возможностей, оптимизации процессов.
Как легко убедиться, большие данные в то же время могут быть очень маленькими. Примером служат потоковые данные с датчиков современного реактивного самолета: здесь работают одновременно сотни тысяч датчиков, каждый датчик производит восемь байтов информации в секунду, итого получается чуть меньше 3 Гб данных за час полета (100 000 датчиков × 3600 секунд × 8 байт). В то же время, не все большие наборы действительно большие: так, к большим данным не относятся потоки видеоинформации плюс метаданные, телефонные звонки и т. п. Если попробовать кратко сформулировать тезис, определяющий большие данные, то он звучал бы так: задачи делают данные большими.
Рассмотрим два примера систем, генерирующих большие данные. Первый пример относится к Большому адронному коллайдеру (ускоритель заряженных частиц), и с точки зрения данных его параметры можно сформулировать так:
- Содержит 150 млн. сенсоров, которые регистрируют 40 млн. пересылок в секунду.
- Происходит 600 млн. столкновений в секунду.
- Теоретически формирует объем данных в размере 500 экзабайт в день (500 квинтиллионов байт).
- Выполняет фильтрацию данных — 100 интересных столкновений в секунду, что уменьшает поток данных на 99,999%.
- Ежегодный уровень данных до репликации (2012) — 25 петабайт.
- Накопленный уровень данных после репликации — 200 петабайт.
Второй пример — Sloan Digital Sky Survey (SDSS, Слоановский цифровой небесный обзор), проект исследования звезд и галактик с помощью широкоугольного телескопа. Этот проект с точки зрения данных имеет следующие характеристики:
- Начал сбор астрономической информации в 2000 году.
- За несколько недель собрано данных больше, чем за всю историю астрономии.
- Генерирует объем данных в размере 200 Гб за ночь.
- Хранит 140 Тб данных.
- Широкий синоптический исследовательский телескоп (преемник SDSS) начнет работу в реальном времени в 2016 году и будет формировать такое же количество данных (140 Тб) каждые 5 дней.
Технология In-memory
Использование оперативной памяти в компьютерах является неотъемлемой частью любых вычислений на протяжении всей истории развития вычислительной техники. В течение последнего полувека сложилась устойчивая вычислительная архитектура, в которой оперативной памяти отведена важная роль, но возможности ее использования долгое время ограничивались объемом оперативной памяти, который был весьма незначителен по сравнению с традиционными средствами хранения информации (жесткие диски, ленточные носители). Это было обусловлено, с одной стороны, высокой стоимостью оперативной памяти, а с другой стороны, устойчивыми тенденциями, когда производители аппаратного и программного обеспечения ориентировались при разработке приложений на то, что оперативная память должна иметь небольшой объем и использоваться для хранения только оперативных объемов данных (необходимых в конкретный момент времени). Это повышало нагрузку на контроллеры ввода-вывода, снижало производительность операций, делало операции чтения-записи, которые преобладают в системах класса Enterprise Resource Planning (ERP, Планирование ресурсов предприятия), недостаточно эффективными с точки зрения пропускной способности. Ситуация стала иной с в 2000‑х годах, когда оперативная память начала снижаться в стоимости, увеличиваться в объеме (с точки зрения возможностей размещения информации на единице площади кристалла), а также качественно улучшать свои потребительские свойства (скорость чтения-записи, надежность, компактность). Меняется ситуация и в вычислительной технике в целом: появляются многоядерные архитектуры (до 96 ядер на сервер), снижается стоимость серверов (до 50 000 USD за один корпоративный сервер), появляется возможность распределять задачи между серверами. Меняется архитектура процессоров, появляется 64-разрядная адресация памяти, в современных серверах становится доступно до 2 Тб оперативной памяти, пропускная способность возрастает до 25 Гб в секунду на ядро, кривая зависимости скорости вычислений от их стоимости идет вниз.
Другим важным фактором, предопределившим появление технологии In-memory, стало развитие концепции колоночно-ориентированного хранения данных (колоночное хранение данных). По сравнению с традиционным строчно-ориентированным способом данные при колоночном хранении содержатся в столбцах, а не в строках. При колоночном хранении данных последовательное сканирование позволяет достичь лучшей производительности обмена данными между процессорами и памятью. Кроме того, независимость кортежей внутри столбцов позволяет легкое партицирование (сегментирование) данных между серверами и, следовательно, их параллельную обработку. Еще одним важным преимуществом колоночного хранения является возможность достаточно эффективной компрессии данных, что позволяет сократить их объем и увеличить скорость извлечения за счет более поздней «материализации» (декомпрессии) данных. Также колоночное хранение позволяет более эффективно выполнять объединение и агрегацию данных.
Пример использования технологии In-memory для решения практических задач в медицине
Задача расшифровки генома человека выла поставлена в 80‑е годы прошлого столетия, десятилетием позже проект официально стартовал в США, и еще через десятилетие — в 2000‑м году — был анонсирован первый вариант расшифрованного генома человека. В то время длительность расшифровки генома и стоимость потребных для этого вычислительных ресурсов делали задачу актуальной только для академической науки, в то время как переход к массовому лечению с использованием данных генома конкретных людей было практически невозможно. В то же время, спектр применения данных расшифровки генома человека чрезвычайно широк: например, пораженные ткани пациентов с опухолью анализируют, чтобы принять конкретные решения в рамках индивидуального лечения, или, например, подозреваемых в преступлениях людей идентифицируют по профилю ДНК. Вместе с этим, направления исследований не ограничиваются ДНК людей. Например, улучшенные зерна отбирают, основываясь на результатах их генетического анализа для повышения урожайности агрокультур в различных регионах мира. Все примеры имеют нечто общее — данные генома, которые огромны. Например, геном человека состоит из 3,2 млрд. пар нуклеотидов. Решить задачу применения данных расшифровки генома в массовой медицине призвана инновационная технология in-memory, исследуемая в институте HPI [3] и изначально разработанная для быстрого анализа больших объемов данных. В HPI был представлен проект расшифровки генома человека с использованием технологии in-memory. Исходная предпосылка к использованию in-memory базировалась на том, что для назначения правильного лечения врачи должны обрабатывать все больше и больше данных с точки зрения понимания генетических изменений, например в ДНК человека. Это вовлекает огромное количество данных, так как каждый человек несет в себе приблизительно 3,2 млрд. частиц генетической информации. Исследователи HPI обрабатывали этот гигантский объем данных с помощью высокопроизводительного компьютера. Для того чтобы проанализировать генетические изменения в реальном времени, ученые комбинировали исследовательские результаты мировых медицинских баз данных с результатами исследовательской базы данных. Высокопроизводительные компьютеры, в комбинации с огромными массивами памяти, помогли исследователям в идентификации известных генетических диспозиций и интерактивном определении дополнительной релевантной для лечения информации. Таким образом, метод (см. Рис.1), на который раньше могли уходить дни и даже недели, теперь можно применить за секунды. Это позволяет врачам и исследователям не тратить драгоценное время на изучение литературы и Интернета, а интегрировать все последние знания о болезни в лечение тут же — в реальном времени.
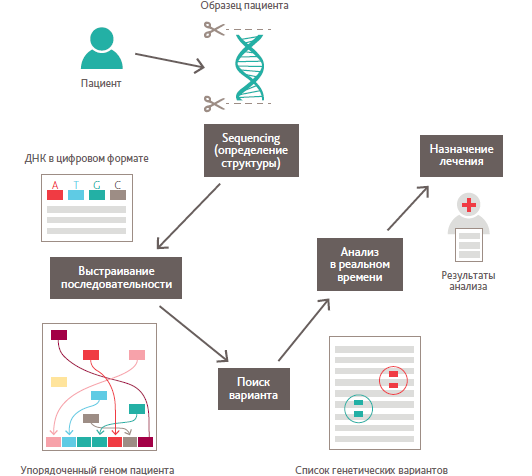
Рис.1. Метод назначения лечения пациенту с использованием расшифрованного средствами технологии in-memory генома человека
Технология RFID
Как известно, ключевой особенностью «Интернета вещей» является тотальное подключение к нему различных устройств, от простейших датчиков до сложных вычислительных систем. Ключевое место в этом ряду занимает технология радиочастотной идентификации объектов (RFID), для которой принцип функционирования заключается в закреплении на объекте RFID-метки (радиоэлектронного устройства) и записи/ считывания данных метки при ее перемещении через поле антенн RFID-считывателя. Это позволяет фиксировать факт нахождения физического объекта в определенном месте и считать всю необходимую информацию об объекте (название, уникальный код объекта и т. д.). По сравнению с другими технологиями
Если хотите прочитать статью полностью и оставить свои комментарии присоединяйтесь к sapland
ЗарегистрироватьсяУ вас уже есть учетная запись?
Войти