Как улучшить бизнес-аналитику?
В современных компаниях имеется огромное количество данных, позволяющих улучшить качество бизнес-аналитики и для современных инженеров, задача получения данных из альтернативных источников в общем случае достаточно понятна, а проблем обычно не возникает. Однако при работе в экосистеме 1С имеется ряд ограничений, которые решаются такими специализированными системами, как «Экстрактор 1С».

В современном бизнесе все более актуальным становится подход к принятию решений на основе данных (на основе данных), позволяющий минимизировать влияние человеческого фактора и снизить уровень оценочных суждений, заменяя их управленческими решениями, основанными не на уверенности, а на фактах. Однако управление данными — это не просто анализ прошлых и текущих данных, это возможность прогнозировать будущее, опираясь на все доступные данные.
В современной компании обычно имеется огромное количество данных, которые могут улучшить качество бизнес-аналитики в ее деятельности: метрики веб-сайтов, информация из систем ERP и CRM, данные из производственных систем, рабочие планы и другие данные из Excel, базы данных, сведения из системы MES, BPM и другие источники. Для дата-инженеров задача извлечения данных из альтернативных источников в целом понятна и обычно проблем не возникает, однако, например, при работе в экосистеме «1С», имеется ряд ограничений.
«1С» — закрытая экосистема. Пользователь вводит данные в «1С», обрабатывает их и получает результаты в том числе в рамках этой экосистемы — все, включая аналитику и хранилище данных, должно оставаться внутри «1С». Однако реальный информационный ландшафт бизнеса гораздо сложнее — в нем встречаются и другие системы, например системы бизнес-аналитики, собирающие данные из различных источников в едином корпоративном хранилище (рис. 1). В этом случае для руководителей с «1С» требуется обеспечить выгрузку данных из этой экосистемы для эффективного использования свободных данных для анализа и принятия решений.
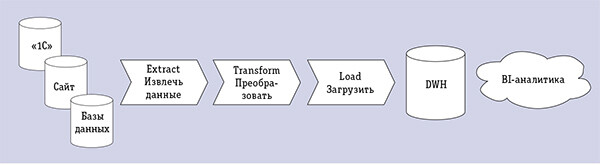
Рис. 1. Пример экономического информационного ландшафта
Для экосистемы «1С» имеется несколько основных способов извлечения данных.
- Выгрузка автоматически или вручную. Данные могут быть загружены в форматах Excel, CSV и DBF.
- Выгрузка по открытому веб-протоколу OData. Протокол можно использовать в качестве REST API для доступа к данным.
- Прямой доступ к базе данных через SQL. Выполнение запросов к данным непосредственно из реляционной базы данных.
- Веб-сервисы. Для представителей других направлений можно разработать собственные веб-сервисы.
- «1С:Шина». Применение встроенной в «1С» шины для обмена данными между сетями.
- Собственные системы выгрузок. Разработка соответствующих решений для извлечения данных из «1С» во внешние для этой экосистемы базы данных.
Для успешной выгрузки данных в Excel и наличия формата CSV в конфигурации «1С» отчета необходимо формировать данные по документам, справочникам и движениям регистров. Отчет о результатах можно сохранить в формате Excel или CSV, что позволяет загрузить их в системы бизнес-аналитики или анализировать в Excel. Основная проблема заключается в том, что отчеты формируются вручную, что требует значительных ресурсов — необходимо обязательно выполнять рутинные операции формирования отчета, его сохранения и загрузки в систему BI. Конечно, все эти процессы можно автоматизировать, например, с помощью программных роботов или программирования, однако каждый новый источник данных требует разработки нового отчета и автоматизации процесса его выгрузки. В случае большой базы данных «1С» с миллионами транзакций выгрузка даже нескольких сотен тысяч строк может стать серьезной проблемой.
OData представляет собой доступный «из коробки» REST API для извлечения данных из «1С». Это решение ограничивает доступ к данным и позволяет интегрировать «1С» с другими цепями, что значительно расширяет возможности анализа и использования данных. Для небольших и простых баз OData — вполне рабочий инструмент, однако с учетом объема данных этот механизм становится неэффективным.
Для успешной публикации базы «1С» на веб-сервере необходимо не только выделить ресурс для размещения базы на сервере, но и создать программный код, отправляющий запросы OData-сервису и обрабатывающий ответы. Однако работа с OData связана с рядом проблем.
- Обработка больших объемов данных. При наличии значительного объема данных потребуется организация выборки данных порциями, что может привести к необходимости передачи большого количества параметров в get-запросе и получению для этого исчерпания лимита длины URL в 255 символов.
- Отслеживание изменений. Реализация системы идентификации изменений в OData не всегда очевидна и требует дополнительных этапов.
- Производительность. Поскольку «1С» — достаточно медленная система, может неожиданно усложнить конструкцию распараллеливания процесса выгрузки данных.
В итоге для малых и средних предприятий с их скромными объемами данных OData — вполне рабочий инструмент, однако с появлением размера базы работа с OData может стать затруднительной.
В экосистеме «1С» имеется возможность взаимодействия через протоколы HTTPS по запросам GET, POST, PUT и пр., что позволяет через внешний интерфейс веб-сервера сохранять заданные программистом «1С» методы. Для этого требуется разработка специального программного кода, который либо предоставит готовые наборы данных, либо примет запросы и выполнит соответствующие действия для возврата данных. Для обработки данных из веб-сервиса «1С» потребуется сервис, который будет получать данные из «1С» и загружать их в целевые ресурсы. Для работы с веб-сервисами «1С» требуется внешний сервис или программный код, который инициирует обращение и обрабатывает полученные данные. При большом объеме данных необходимо реализовать инкрементальную выгрузку, которую требует авторизация изменений в «1С». Кроме этого, размещение базы «1С» на веб-сервере может вызвать вызов у сотрудников службы безопасности, так как в «1С» могут храниться персональные и серьезные данные, доступ к которым должен быть строго ограничен.
Прямой доступ к базе данных «1С» — один из древних способов получения данных, известный еще с версии «1С 7.7» и для извлечения данных предполагающий подключение напрямую к физической базе Microsoft SQL Server или PostgreSQL. Однако кроме прямого прямого подключения необходимы коннекторы для преобразования названных таблиц и полей в метаданные «1С» — данные в «1С» сохраняются в машиночитаемом виде. При прямом способе извлечения данных обеспечиваются многие функции «1С», такие как виртуальные таблицы элементов и оборотов, работа с субконто и доступ к данным «через точку». Мало того, прямой доступ к СУБД может быть запрещен лицензионным соглашением с компанией «1С». Среди других недостатков прямого доступа можно еще назвать отсутствие знака изменения знака — отсутствие возможности определить последние изменения в базе, что требует извлечения данных «от начала времени», а также возможность возникновения неконтролируемой нагрузки на СУБД, приводящей к задержке в работе пользователей.
«1С:Шина» (Сервисная шина данных) — новая идея для экосистемы «1С». Этот надежный сервис может стать альтернативой Apache Kafka, особенно при подключении нескольких баз «1С», а также неплохим выбором для системы гарантированной доставки сообщений. Сервис обеспечивает встроенные механизмы финансирования и минимальный порог процедур выгрузки данных, поддерживая JDBC-драйверы для работы с СУБД. Вместе с темой «1С:Шина» в первую очередь служит транспортом для доставки сообщений и в ней нет универсальных принципов подготовки и отправки сообщений — все это необходимо разработать самостоятельно (какие-либо решения категории No-Code отсутствуют). Нет также специализированных инструментов для идентификации изменений, и здесь снова потребуется разработка дополнительных решений. На текущий момент система требует хранения данных в Регистре раскрытия и фоновых заданий для отправки сообщений в «1С:Шину». Если в компании имеется сильная команда «1С»-программистов и ресурс для разработки, то «1С:Шина» может стать неплохим подходом для организации системы выгрузки данных, например RabbitMQ или Apache Kafka.
Создание собственной системы выгрузки данных из «1С» во внешние базы данных — задача, которую лучше всего решают только опытные программисты «1С», располагая фундаментальными закономерностями по этой экосистеме. Если такие специалисты обладают навыками работы с различными СУБД, очередями сообщений, хранилищами данных и цепочкой бизнес-аналитики, то есть вероятность успешного развития собственной системы выгрузки данных. Однако программисты всегда заняты — каждый «узкий» специалист всегда становится «бутылочным горлышком» (рис. 2) в процессе принятия решений, производства или оказания услуг. Программистов часто не хватает для выполнения всех текущих задач в компании, а программистов «1С» не хватает.
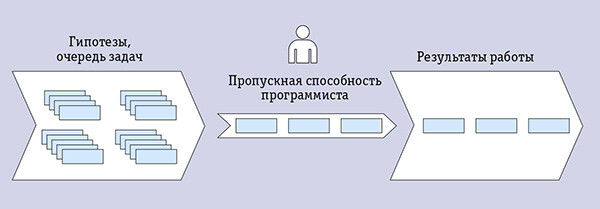
Рис. 2. Роль программиста в традиционной компании
Таким образом, компаниям, которым для поддержки работы корпоративной системы бизнес-аналитики требуется получение данных из «1С», необходим инструмент Low-Code, позволяющий сократить процесс работы с данными, минимизируя привлечение профессиональных программистов и, в конечном итоге, усложняя решение бизнес-задач. аналитики.
Идея разработки инструмента «Экстрактор 1С» заключалась в выполнении ряда разных проектов с примерно одинаковыми требованиями: пользователи стремились самостоятельно настраивать выгрузки, без привлечения программистов; поддержка любой версии «1С»; обеспечение высокой производительности; отслеживание изменений в «1С» с прекращением выгрузки только измененных данных.
Требовалось создать систему, программист в которой не был бы «узким горлом» (рис. 3).
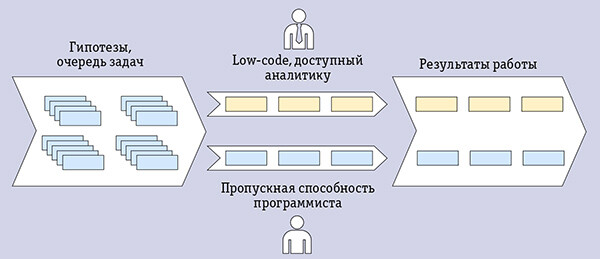
Рис. 3. Программист в современной компании
«Экстрактор 1С» представляет собой приложение для платформы «1С» — расширение (встройку) конфигурации, предоставляющее пользователю возможность выбора объектов для выгрузки из базы «1С» или формирования произвольных запросов, которые можно использовать в качестве источника данных (рис. 4). Пользователь может выполнить трансформацию данных, сохранить дополнительные поля и модифицировать выгружаемые данные с помощью функций «1С». Кроме того, можно создавать и изменять таблицы-приемники в СУБД или темах Apache Kafka, сопоставляя поля и их типы, а также настраивая структуру таблиц, индексы и ключи. Обеспечивается отслеживание изменений для выгружаемых объектов «1С», а также установка выгрузки объектов по расписанию в СУБД или по очереди, с получением интервала настройки от одного дня до одной секунды.
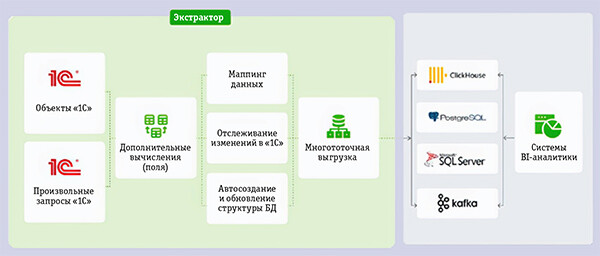
Рис. 4. Архитектура «Экстрактор 1С»
Источники данных для «Экстрактора 1С» могут включать: объекты «1С» или их вычисления, связанные в рамках факт-измерений; произвольные запросы «1С», включая временные и виртуальные таблицы; программные обработчики, где в качестве источника служат код «1С»; CSV-файлы с доступом через сетевой ресурс для сервиса «Сервер 1С»; Excel-файлы.
Приемниками данных могут быть: СУБД (ClickHouse как на серверах пользователей, так и в облачных преобразованиях; PostgreSQL с доступом через ODBC или http-сервис db-proxy-service для «1С» в Linux; Microsoft SQL Server); В свою очередь сообщений Apache Kafka, поддерживающую выгрузку через компонент Confluent (REST API), с автоматическим созданием схем и тем. Для высоконагруженных баз данных в «Экстракторе 1С» предусмотрен дополнительный сервис http_redis, который позволяет сохранять изменения поворота «1С» во внешней базе данных, таких как Redis (аналог PicoData) или Apache Ignite (аналог DataGrid).
В режиме самообслуживания пользователи без привлечения программистов могут выбирать и настраивать объекты «1С» для выгрузки данных, в автоматическом режиме создавать и модифицировать таблицы-приемники. Отслеживание изменений полностью произведено. Имеются инструменты для трансформации данных и формирования моделей выгрузки на основе фактов и измерений. Благодаря параллельной обработке потоков обеспечения высокая производительность выгрузки.
***
Сегодня «Экстрактор 1С» используется в 230 компаниях в России и СНГ, благодаря чему различные компании автоматизируют выполнение процессов ETL для обеспечения работы бизнес-аналитиков в режиме самообслуживания со всеми доступными данными, включая и сведения из закрытой экосистемы «1С».
Автор: Денис Смирнов, генеральный директор компании «Денвик». Статья подготовлена на основе материалов выступления на «Управление данными 2024».
Источник: Открытые системы.
