Транзакция LSMW инструкция по применению. Часть 2
В этой книге приводятся практические решения задач с использованием транзакции
LSMW для загрузки данных на основе методов Batch Input, BAPI и
Direct Input. Примеры базируются на бизнес-сценарии миграции данных.
Продолжение книги.
Шаг 3: создание структуры источника [данных]
Дважды щелкаем по пункту Maintain Source Structures (рис. 1.28). Нажимаем кнопку Create a Structure (рис. 1.29) и вводим данные для новой структуры, затем подтверждаем ввод (рис. 1.29.а). В качестве ID структуры зададим ZMATIA1, в качестве описания — PresentationServer: Inactive Materials.
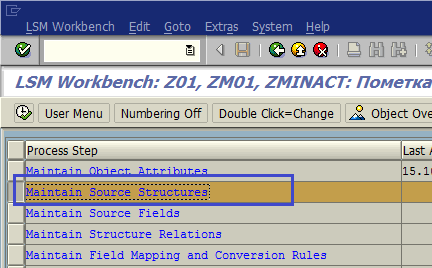
Рис. 1.28. Переходим к пункту Maintain Source Structures
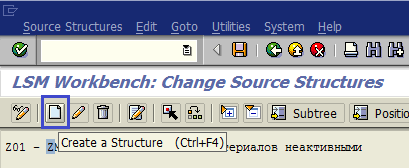
Рис. 1.29. Создание структуры входных данных
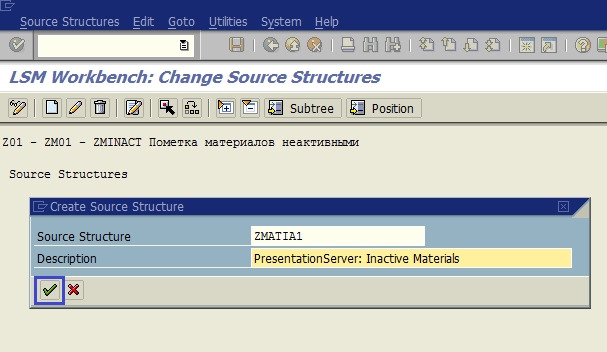
Рис. 1.29.а. Указываем ID и описание структуры, затем подтверждаем ввод
Получаем экран, как представлен на рис. 1.30. Затем сохраняем и выходим к экрану обзора шагов, чтобы перейти к следующему шагу.
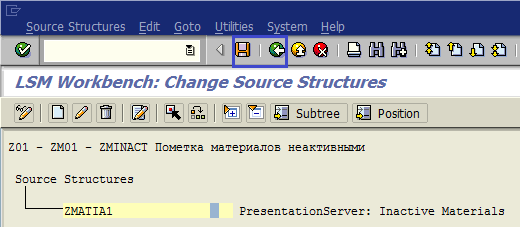
Рис. 1.30. После создания структуры сохраняем и выходим к основному меню
Шаг 4: ведение полей структуры источника [данных]
Щелкаем дважды по пункту Maintain Source Fields (рис. 1.31). Ставим курсор на имя структуры ZMATIA1 (PresentationServer: Inactive Materials) и нажимаем кнопку Create Source Field (рис. 1.32). В качестве имен полей лучше использовать имена, предложенные в шаге 2 (Создание записи, таблица 4). Это поможет не запутаться в данных и использовать AutoMapping на одном из следующих этапов. Система предложит детальный экран создания поля входной структуры (рис. 1.33). Однако для ввода полей можно использовать и табличный ввод. Ставим курсор на структуру и нажимаем кнопку Table Maintenance (рис. 1.34). Вводим нужные данные, сохраняем и выходим к основному экрану шага (рис. 1.35).
Рис. 1.31. Переходим к Maintain Source Fields (Ведение полей источника данных)
Рис. 1.32. Выделяем нужную структуру и нажимаем кнопку Create Field ( Создание поля)
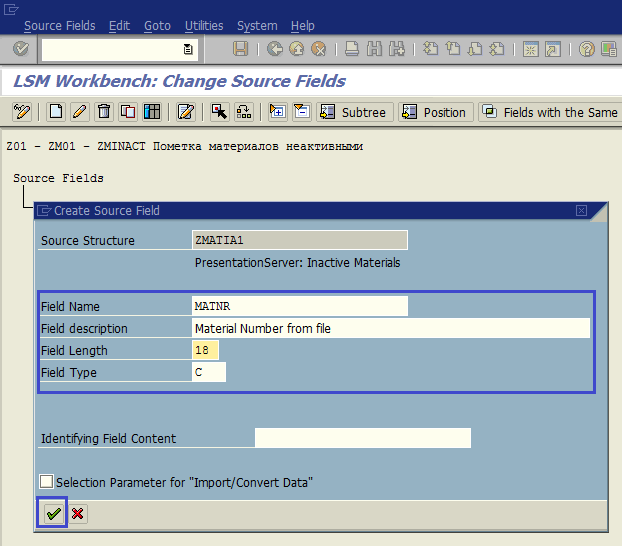
Рис. 1.33. Детальный экран указания поля входной структуры
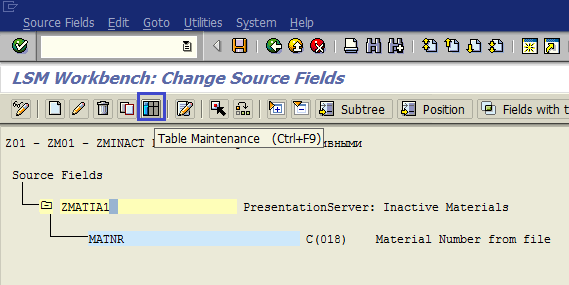
Рис. 1.34. Переход к табличному вводу новых полей структуры источника данных
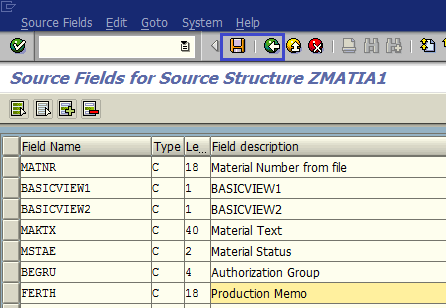
Рис. 1.35. Вводим поля, необходимые для загрузки данных
Введенные данные представлены в таблице 1.5.
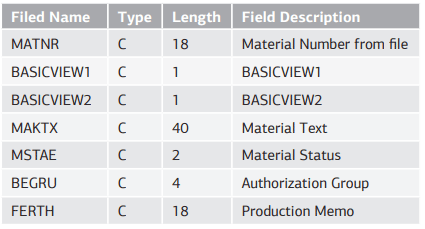
Табл. 1.5. Технические имена полей входной структуры данных
В основном экране шага сохраняем данные и выходим к обзору шагов, чтобы перейти к следующему шагу (рис. 1.36).
Рис. 1.36. Сохраняем полученный результат и переходим к основному меню транзакции LSMW
Шаг 5: соответствие структур источника данных и записи
Дважды щелкаем по шагу Maintain Structure Relations (рис. 1.37).
Рис. 1.37. Переходим к пункту Maintain Structure Relation (Присвоение входных и внутренних структур)
На этом шаге нам необходимо произвести соответствие между внутренней структурой данных (то есть полями записи) и структурой источника [данных]. В нашем случае (метод записи — метод пакетного ввода) данный шаг выполняется чаще всего автоматически; и от того, кто готовит загрузчик, требуется подтвердить привязку: сохранить и выйти к обзору шагов, чтобы перейти к следующему шагу (рис. 1.38).
Рис. 1.38. Сохранение и подтверждение присвоения структур
Шаг 6: мэппинг (соответствие) полей источника [данных] и полей записи пакетного ввода
Дважды щелкаем по шагу Maintain Field Mapping and Conversion Rules (рис. 1.39). Это весьма важный шаг, так как именно здесь задаются мэппинг и правила конвертации данных. Именно на основе конвертированных данных происходит реальная загрузка данных.
Рис. 1.39. Переход к шагу мэппинга и правил конвертации
На этом шаге необходимо произвести мэппинг полей между структурой записи пакетного ввода и структурой входного источника данных. Так как мы обозначили ID полей одинаково как в структуре записи, так и во входном файле, то мы можем использовать функцию AutoMapping. Для этого переходим по меню в открывшемся экране: Extras -> Auto-Field Mapping (рис. 1.40).
Рис. 1.40. Запуск функции Auto Field Mapping для мэппинга полей
Система откроет экран настроек функции Auto Field Mapping (рис. 1.41). Здесь можно указать, насколько должны совпадать имена полей, чтобы произвести мэппинг, а также какое правило конвертации применять. В нашем случае, когда поля совпадают полностью, нужен простой перенос значения (правило MOVE) из входной структуры во внутреннюю. В опциях ставим No Confirmation и получаем результат (рис. 1.41, 42).
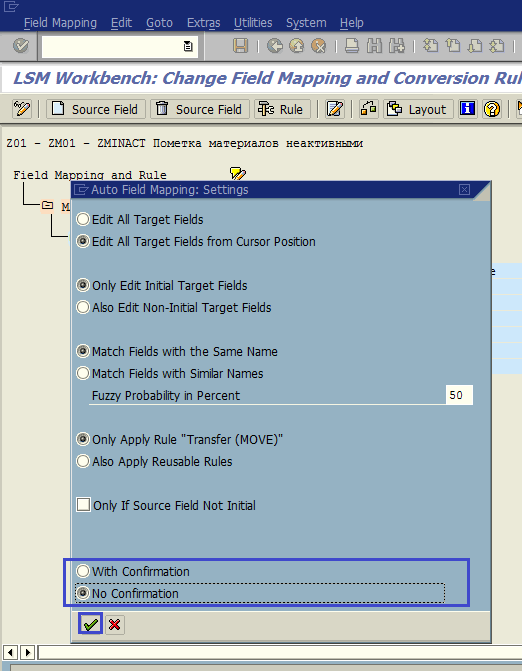
Рис. 1.41. Настройка Auto Field Mapping
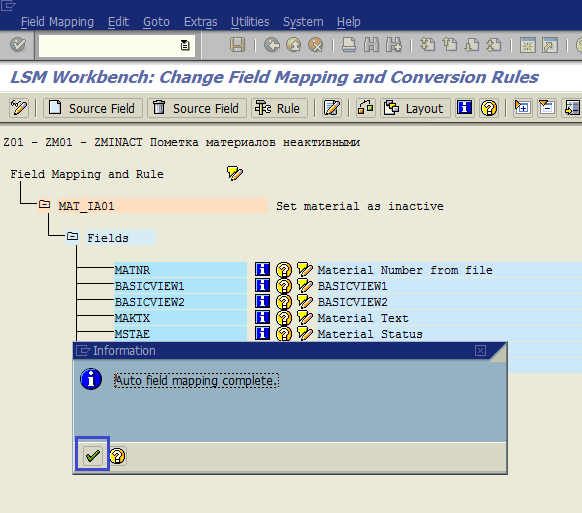
Рис. 1.42. Подтверждение работы функции Auto Field Mapping
Система покажет проведенный Auto Mapping полей. В нашем случае система произвела правильный автомэппинг (рис. 1.42). В случае необходимости мы можем вручную изменить что-нибудь. А именно мы назначим постоянные значения полей и ABAP-код для поля MAKTX. Поставим курсор на поле BASICVIEW1 нажмем кнопку Constant на панели инструментов (рис. 1.43).
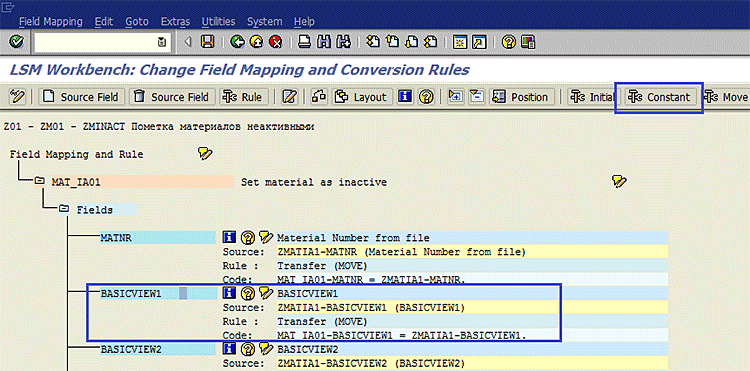
Рис. 1.43. Выбираем поле BASICVIEW1 и нажимаем кнопку Constant
В появившемся окне поставим в качестве постоянного значения X и подтвердим ввод (рис. 1.44).
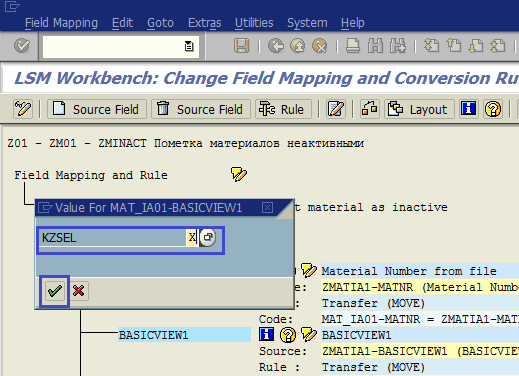
Рис. 1.44. Присваиваем постоянное значение X полю BASICVIEW1
Постоянные значения также проставим и для других полей. Данные представлены в таблице 1.6.

Табл. 1.6. Правила конвертации (conversion rules) для полей загрузчика
Для поля MAKTX (Material text) мы создадим правило согласно нашим требованиям: добавить prefix NotInUse в текст материала. Поставим курсор на поле MAKTX и нажмем кнопку Rule (рис. 1.45). В качестве правила выберем ABAP-code (рис. 1.46). После ввода требуемого ABAP-правила нажимаем Сохранить и выходим в основной экран шага (рис. 1.47).
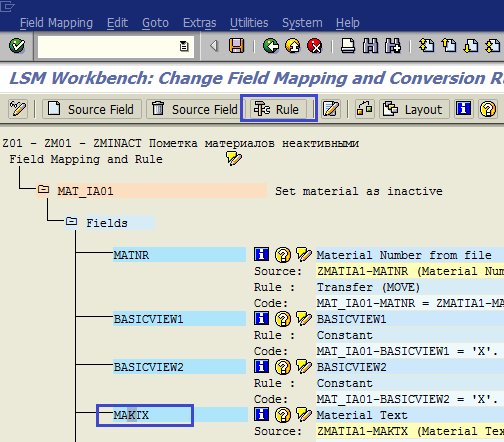
Рис. 1.45. Для вставки дополнительного ABAP-правила выделяем нужное поле и нажимаем кнопку Rule
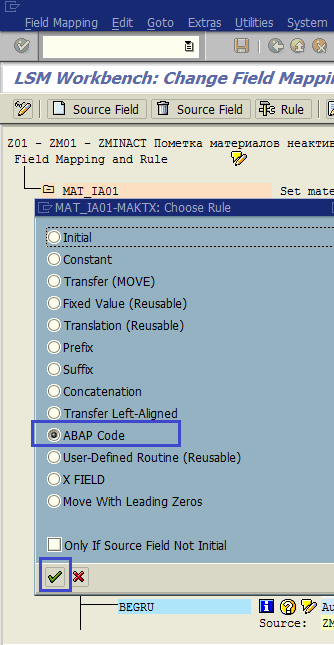
Рис. 1.46. Выбираем правило ABAP-код (ABAP-rule) (ABAP и подтверждаем ввод
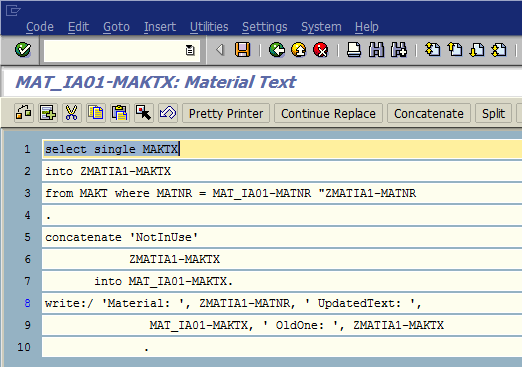
Рис. 1.47. Вставляем код по редактированию текста материала
Мы задали мэппинг и назначили правила обработки всем полям. Сохраняем наш результат и переходим к экрану обзора шагов, чтобы перейти к следующему шагу (рис. 1.48).
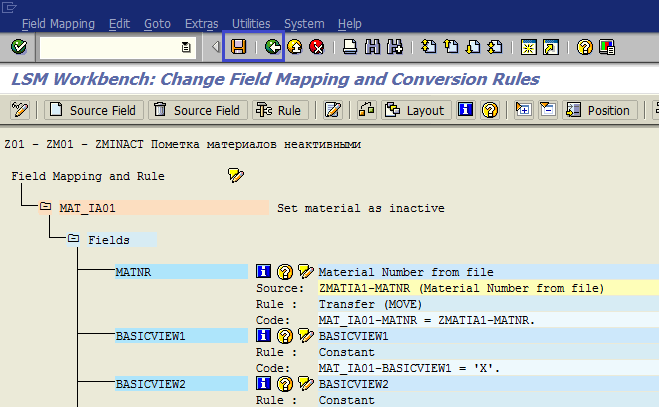
Рис. 1.48. Сохраняем мэппинг и правила конвертации и выходим в основное меню транзакции LSMW
Шаг 7: указание пути к файлу
После мэппинга полей следующим шагом может быть шаг Maintain Fixed Values, Translations, User-Defined Routines. Об этом шаге будет рассказано позже. В качестве следующего шага будет Specify Files. Однако, прежде чем указывать путь к файлу, необходимо создать файл нужного нам формата. Для создания входного файла будем использовать Excel. Первый файл для проверки загрузчика разумно создавать на 2–3 записи; так как в случае проблем можно их быстро устранить. Первую строку в Excel заполнить техническими именами полей входной структуры . А строки, начиная со 2-й, заполним уже конкретными значениями (рис. 1.49).
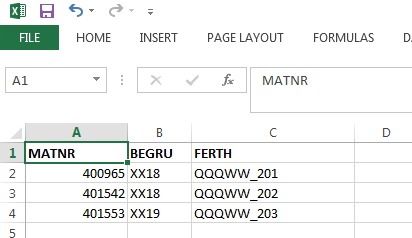
Рис. 1.49. Заполняем Excel-файл по нужному шаблону
Затем мы сохраним Excel как файл в формате xlsx, скопируем все данные и сохраним в блокноте (в формате .txt) (можно выполнить операцию Save As — Сохранить как). На выходе должен получиться файл в формате txt с табуляторами в качестве разделителей (рис. 1.50).
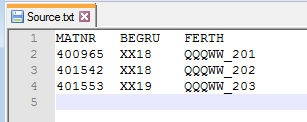
Рис. 1.50. Файл с расширением .txt с табуляторами в качестве разделителей
После создания текстового файла переходим к указанию его в качестве файла-источника. Дважды щелкаем по шагу Specify Files (рис. 1.51).
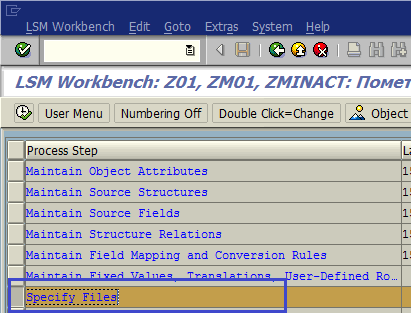
Рис. 1.51. Переходим к пункту Specify Files для указания файла с данными
Ставим курсор на строку On the PC (Frontend) и нажимаем кнопку Add Entry (рис. 1.52).
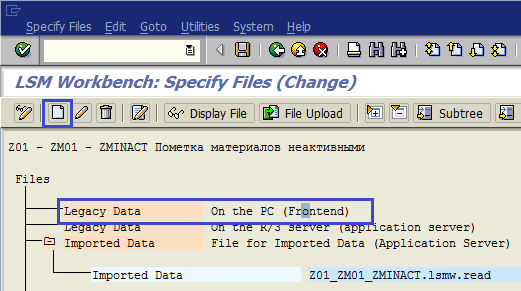
Рис. 1.52. Указываем файл для загрузки данных
Указываем путь к файлу, имя файла (то описание, которое мы хотим видеть на экране); в качестве разделителя указываем Tabulator и отмечаем флажок Field Named at Start of File. Подтверждаем
Если хотите прочитать статью полностью и оставить свои комментарии присоединяйтесь к sapland
ЗарегистрироватьсяУ вас уже есть учетная запись?
Войти