Большие данные в SAP Leonardo*
Данные — это валюта современного цифрового предприятия. Для успешного перехода в цифровой формат компании важно уметь эффективно переносить, преобразовывать и интегрировать данные, а также повышать их качество.

*Оригинал (англ.): SAP Leonardo. Введение в интеллектуальное предприятие. Пьер Эразмус, Вивек Винаяк Рао, Амит Синха, Ганеш Вадавадиги. Издательство SAP PRESS. Глава 3. 2019.
Данные — это валюта современного цифрового предприятия. Для успешного перехода в цифровой формат компании важно уметь эффективно переносить, преобразовывать и интегрировать данные, а также повышать их качество. Причём важно уметь это делать с данными любого типа, из любого источника и с любой периодичностью. Чтобы получать из больших данных ценные сведения, требуется готовое распределённое вычислительное решение уровня предприятия.
Большие данные характеризуются высоким объёмом, скоростью и разнообразием. Под высоким объёмом подразумевается большое количество данных, измеряемое терабайтами и петабайтами. Высокая скорость относится к скорости создания данных, особенно это характерно для данных потоковой передачи из нескольких источников, например, с датчиков в Интернете вещей (IoT). Высокое разнообразие предполагает, что здесь можно выделить данные самых разных типов: структурированные, неструктурированные и полуструктурированные. Сейчас компании собирают данные по всем измерениям. В отличие от прошлого, когда большая часть данных имела транзакционный характер, реляционные базы данных не отвечают современным требованиям в реальности больших данных в вопросах хранения, обработки и использования данных.
ИТ-стратегия компании должна отражать современные технологические тенденции: сокращение объёмов и объединение разрозненных данных, управление облачными и гибридными стратегиями развёртывания, эффективное применение новых вариантов архитектуры данных (например, так называемых озёр неструктурированных данных) и обработка данных новых типов (например, пространственные и потоковые данные IoT).
В этой главе мы сначала рассмотрим общее понятие больших данных. Вы узнаете, что собой представляют большие данные и для чего они нужны. Далее мы познакомимся с инструментами и продуктами SAP, поддерживающими эту технологию, и изучим ряд примеров из разных отраслей и направлений бизнеса, важную роль в которых сыграли эти инструменты и продукты.
Что представляют собой большие данные (раздел 3.1)
Данные заняли центральное место во многих компаниях, особенно с наступлением эпохи больших данных и появлением новых источников данных: потоковая передача, социальные сети и другие типы неструктурированных данных. Мы по-прежнему можем пользоваться транзакционными базами данных при выполнении базовых бизнес-процессов, но новые источники занимают всё более важное место и проявляют себя абсолютно новыми способами. Универсальная структура данных — подход к созданию архитектуры и набор сервисов данных для предоставления непротиворечивых возможностей и сервисов для локальных и мультиоблачных сред, который помогает упростить управление интеграцией данных и реализовать переход компании в цифровой формат. Эта универсальная структура данных даёт ответы на вопросы, возникающие в процессе работы:
- Нужно ли иметь различные специализированные базы данных для разных типов данных?
- Должна ли каждая база данных работать в собственной среде?
- Как избежать задержек в результате интеграции различных сред?
Такая архитектура также отвечает следующим требованиям.
- Производительность
Инфраструктура, которая предоставляет данные с высокой скоростью для удовлетворения потребностей пользователей, эффективного выполнения процессов и решения бизнес-задач.
- Свобода
По мере создания данных пользователями, системами (облачными и локальными) и всевозможными внешними сторонами необходимо обеспечить их свободное и неограниченное перемещение в потоках.
- Модели данных
Вам потребуется моделировать данные для достижения определённых бизнес-целей. При работе с большими данными критическое значение приобретает обнаружение данных для выявления взаимосвязей и скрытых ценных сведений.
- Независимость
Важно обеспечить возможность масштабирования. Доступные вычислительные мощности не должны ограничивать данные, а данные не должны ограничивать вычислительные мощности.
- Низкое значение задержки
Несмотря на то, что данные создаются с беспрецедентной скоростью, чтобы обеспечить выполнение всех потребностей компании, данные должны быть доступны для включения в транзакции, автоматизированные процессы и аналитику сразу же после создания.
- Управление
При обеспечении доступности данных и возможности их использования не следует пренебрегать их целостностью и безопасностью.
- Беспрепятственное выполнение
Необходимо обеспечить полную совместимость и согласованность для объединения структурированных данных и новых источников данных, поскольку данные создаются без представления степени сложности различных типов данных.
Кроме того, с течением времени типичный ландшафт компании для управления данными развивается в соответствии с описанными ниже бизнес-потребностями.
- Корпоративные хранилища данных
Обычно для поддержки всего предприятия используется одно хранилище данных. Эта потребность вырастает из необходимости обеспечить подключение процессов в транзакционных приложениях с последующей интеграцией транзакционных процессов с бизнес-аналитикой предприятия.
- Информационные витрины
Инфо-витрины позволяют собирать данные из нескольких источников для оптимизации и поддержки бизнес-целей или бизнес-потребностей. Часто инфо-витрины проходят оптимизацию для того, чтобы оперативно предоставлять ответы на бизнес-вопросы для принятия решений о выполнении действий.
- Озёра данных
Обычно так называют платформу больших данных (Hadoop или Spark), которая используется для хранения и изучения всех потоков необработанных данных IoT с разных датчиков в нескольких местоположениях внутри компании и за её пределами. Далее данные переносятся из озера в хранилище или инфо-витрину для организации и уточнения, чтобы их можно было применять в процессе принятия решений на всех уровнях организации.
Эти задачи выполняет решение SAP HANA Data Management Suite, которое позволяет собирать и объединять данные всех типов в реальном времени и на одной платформе. С помощью SAP HANA Data Management Suite можно остановить беспорядочное разрастание объёмов данных, выполнять мгновенный анализ данных и устранять неразрешимые бизнес-проблемы, в значительной мере упрощая путь компании к интеллектуальному предприятию. Как показано на Рис. 3.1, SAP HANA Data Management Suite предоставляет безопасные и управляемые корпоративные приложения и средства аналитики в открытом гибридном пакете решений с несколькими облаками, с помощью которых вы сможете гармонизировать достоверные данные и эффективно организовать их в едином ландшафте.
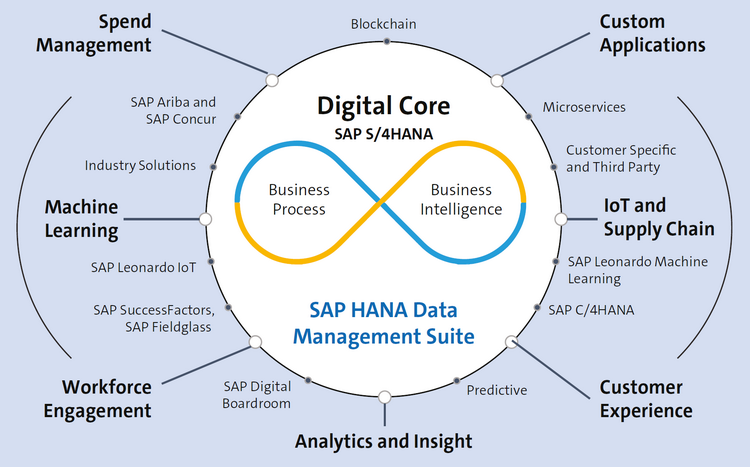
Рис. 3.1 Пакет решений для управления данными на базе SAP HANA для интеллектуальных предприятий
Перевод надписей на картинке:
Решение SAP HANA Data Management Suite обеспечивает сквозное управление данными от регистрации, получения и обработки до гармонизации, вычисления и потребления. В рамках этих процессов SAP HANA Data Management Suite может выступать как фабрика принятия решений, очищая необработанные данные и преобразуя их в доверительный формат для последующего использования в приложениях, средствах аналитики, машинном обучении и других функциях. Одновременно это платформа разработки для приложений, которым требуется получать результаты аналитики по транзакциям в реальном времени, для управления данными, их обезличивания и направления в потоках по защищённым каналам для дополнительного уточнения в ландшафте. С помощью этой платформы можно выполнять моделирование по всем направлениям бизнеса, обрабатывать различные типы данных и технологических архитектур, выполнять анализ данных в оперативной памяти с применением нескольких моделей, а также обрабатывать данные в распределённой вычислительной структуре.
Как показано на Рис. 3.2, SAP HANA, SAP Data Hub, и SAP Cloud Platform Big Data Services являются ключевыми инструментами SAP HANA Data Management Suite для работы с большими данными. В следующих разделах мы познакомимся с ними поближе.
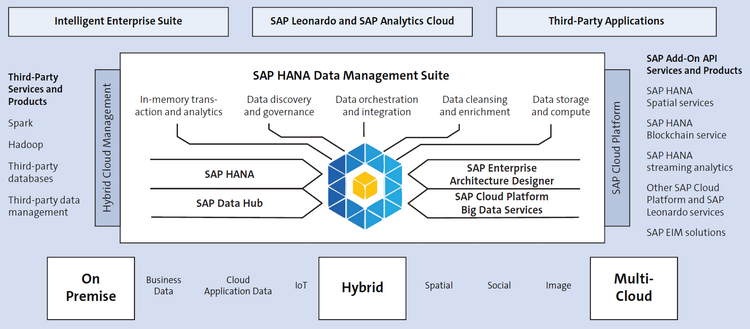
Рис. 3.2 Пакет решений для управления данными на базе SAP HANA
Перевод надписей на картинке:
Универсальная платформа для управления данными (раздел 3.2)
SAP HANA, как показано на Рис. 3.3, предоставляет архитектуру обработки данных, разработанную специально для решения задач вывода данных в соответствии с современными требованиями и стандартами, что позволяет компаниям с лёгкостью получать все преимущества применения новых технологий. Вы можете выполнять аналитику по актуальным транзакциям в режиме реального времени без тиражирования данных виртуально или физически, подключаясь ко всем данным из любого источника. По сути, SAP HANA делает следующий шаг и предоставляет гибридную платформу следующего поколения для транзакционной и аналитической обработки (HTAP) с уникальной способностью не только выполнять задачи операционной аналитики с неструктурированными данными (например, в бизнес-операциях), но и применять расширенные возможности аналитической обработки: прогнозное машинное обучение или обработку структурированных и неструктурированных данных на естественном языке (сюда относятся графические данные, пространственные данные, текст, хранилища документов, средства поиска и потоки данных в реальном времени).
Оформите подписку sappro и получите полный доступ к материалам SAPPRO
Оформить подпискуУ вас уже есть подписка?
Войти