Адаптация программ SAP ERP HCM для платформы SAP HANA
Статья посвящена адаптации программ SAP ERP HCM для эффективного применения после миграции на платформу SAP HANA.
Ключевое понятие
SAP HANA — это чрезвычайно быстрая система управления реляционными базами данных с колоночным хранением и обработкой в оперативной памяти, которая позволяет приложениям сохранять и извлекать данные, а также выполнять сложные аналитические вычисления.
Многие компании планируют перейти на платформу SAP HANA, либо уже сделали это. Поэтому важно, чтобы функциональность и структура программ SAP ERP HCM были полностью оптимизированы для эффективного использования вместе с SAP HANA.
В первой статье моего цикла, состоящего из двух частей, описаны важные аспекты создания пользовательского кода при работе на проекте внедрения SAP HANA или при миграции на систему SAP HANA. Там указаны области, на которые необходимо обратить внимание при написании кода, а также моменты, которых следует избегать для корректной работы программы на базе SAP HANA с высокой производительностью.
Начнем с краткого обзора SAP HANA. Далее я расскажу, как следует изменить пользовательский код, чтобы программы выполнялись эффективно. Помимо этого, рассмотрим, какие конструкции или фрагменты кода программы SAP ERP HCM можно оптимизировать для достижения лучших результатов на платформе SAP HANA.
Также я приведу примеры кода SAP ERP HCM с таблицами SAP ERP HCM, наглядно демонстрирующие эффективный код и конструкции, которых лучше избегать.
SAP HANA: обзор
База данных SAP HANA выполняет обработку в оперативной памяти, что позволяет очень быстро выполнять вычисления и извлечение данных. Прежде чем перейти к подробному описанию изменений, которые следует внести в программы SAP ERP HCM, кратко опишем принципы хранения таблиц. До появления платформы SAP HANA данные хранились в таблицах баз данных на основе строк. Однако в SAP HANA также можно хранить данные в архитектуре на основе столбцов. SAP HANA поддерживает хранение как на основе строк, так и колоночное хранение, но архитектура с колоночным хранением является наиболее эффективной.
Изучите данные в таблице T512T. Выполните транзакцию SE11 и в поле Name (Имя) на открывшемся экране введите имя таблицы (T512T). Нажмите кнопку Technical Settings (Технические параметры настройки). На открывшемся экране выберите вкладку DB-Specific Properties (Свойства, специфичные для базы данных), см. Рис. 1.
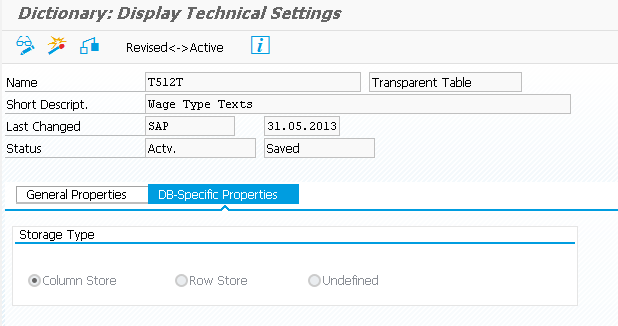
Рис. 1. Свойства, специфичные для базы данных, таблицы T512T
Обратите внимание на то, что для типа хранения соответствующей таблицы выбран переключатель Column Store (Колоночное хранение). Почти во всех таблицах используется архитектура колоночного хранения.
В SAP HANA пул или кластер таблиц отсутствует. Они были преобразованы в прозрачные таблицы. Кроме того, поскольку эта база данных выполняет обработку в оперативной памяти с очень большой скоростью, нет необходимости создавать вторичные индексы в таблицах базы данных, чтобы обеспечить оптимальную производительность.
После завершения миграции на SAP HANA код в стандартной системе SAP (т. е. исходный код SAP) по-прежнему выполняется без каких-либо проблем. SAP скорректировала стандартный код SAP для корректного функционирования в среде SAP HANA. Однако для обеспечения полного объема функциональности и оптимальной производительности пользовательского кода, в том числе в модуле SAP ERP HCM, при работе на платформе SAP HANA требуется некоторая адаптация. Необходимо выполнить следующие три шага:
- После миграции на SAP HANA в некоторых пользовательских программах могут возникнуть синтаксические ошибки. После миграции операторы или конструкции, допустимые в версии до появления SAP HANA, могут перестать работать.
- В некоторых программах синтаксические ошибки могут отсутствовать, однако результаты их выполнения будут некорректны. Сюда относятся программы, которые возвращают отсортированные данные из оператора SELECT.
- Для некоторых программ может потребоваться внести небольшие изменения в традиционный ABAP Open SQL (согласно новым золотым правилам доступа к базе данных), чтобы оптимизировать производительность SAP HANA. В этом шаге не используются какие-либо современные или расширенные функции, например, расширенный Open SQL, ракурсы Core Data Services (CDS) или ABAP-Managed Database Procedures (AMDP). SAP и эксперты по системам SAP рекомендуют выполнить этот шаг. В некоторых случаях это необязательно. Например, стандартный Open SQL обеспечивает достаточный уровень производительности, поэтому выполнение этого шага, подразумевающее большой объем работы, может не иметь заметного эффекта.
Первое задание — убедиться в том, что все пользовательские программы работают правильно и без синтаксических ошибок. Необходимо выполнить полную проверку существующего ABAP-кода. В основном, пользовательский код работает в соответствии с ожиданиями.
После выполнения шагов 1–3 может потребоваться применить более сложные функции ABAP: ракурсы CDS, AMDP и расширенный Open SQL, чтобы передать логику сервера приложений в базу данных для реализации всех возможностей и преимуществ SAP HANA. Описание этих расширенных функций выходит за рамки статьи.
Native SQL
Обязательно удалите (с соответствующей заменой) все фрагменты кода в программе SAP ERP HCM, которые являются специфичными для определенной базы данных, например, Oracle. К типичным примерам относится Native SQL и использование подсказок для базы данных в операторах Open SQL. Это было допустимо использовать до появления SAP HANA, но после миграции на платформу SAP HANA такие фрагменты необходимо удалить. Рассмотрим пример на рис. 2.

Рис. 2. Пример с Native SQL
Итак, в этом коде используется Native SQL. Это очень простой пример, но он позволяет показать детали структуры Native SQL. Эта структура зависит от базы данных, которая будет принимать данный фрагмент кода.
Оформите подписку sappro и получите полный доступ к материалам SAPPRO
Оформить подпискуУ вас уже есть подписка?
Войти
Обсуждения 1
1
Комментарий от
Олег Точенюк
| 16 марта 2019, 17:21