Параллельное программирование c использованием ABAP Concurrency API
Время от времени появляются задачи, в которых необходимо выполнить операции, занимающие продолжительное время.
Введение
Время от времени появляются задачи, в которых необходимо выполнить операции, занимающие продолжительное время. Если операции не зависят друг от друга, то для уменьшения времени выполнения можно использовать параллельное программирование.
Постановка проблемы
Реализация параллельного программирования в ABAP обычно включает следующие шаги:
- Создание RFC функционального модуля (ФМ).
- Реализация внутри него бизнес-логики.
- Асинхронный вызов RFC ФМ в цикле.
- Ожидание выполнения и получение результатов работы.
Если посмотреть на получившийся список, то можно заметить, что по большому счету нас интересуют только шаги 2 и 4. Все остальное — это рутинная работа, которая каждый раз занимает время и потенциально может быть источником ошибок.
Чтобы не создавать RFC ФМ каждый раз, когда необходимо выполнить параллельную обработку, можно использовать SPTA Framework, который нам предоставил вендор.
SPTA Framework — это хороший инструмент, но интерфейс взаимодействия с ним оставляет желать лучшего. Из-за этого разработчику приходится прикладывать немалые усилия для того, чтобы реализовать сам процесс распараллеливания.
Кроме того, написать чистый код, используя непосредственно SPTA Framework, тоже не самая простая задача. Например, нужно хорошо постараться, чтобы избежать использования глобальных переменных. Но если с этим еще можно справиться, то избежать использования подпрограмм (FORM) не выйдет. В конечном итоге код может получиться запутанным и тяжело поддерживаемым.
Решение
Для решения рассмотренных проблем предлагается использовать ABAP Concurrency API.
ABAP Concurrency API – это несколько классов, предназначенных для реализации параллельных вычислений на базе SPTA Framework.
На рис. 1 представлена UML-диаграмма классов ABAP Concurrency API.
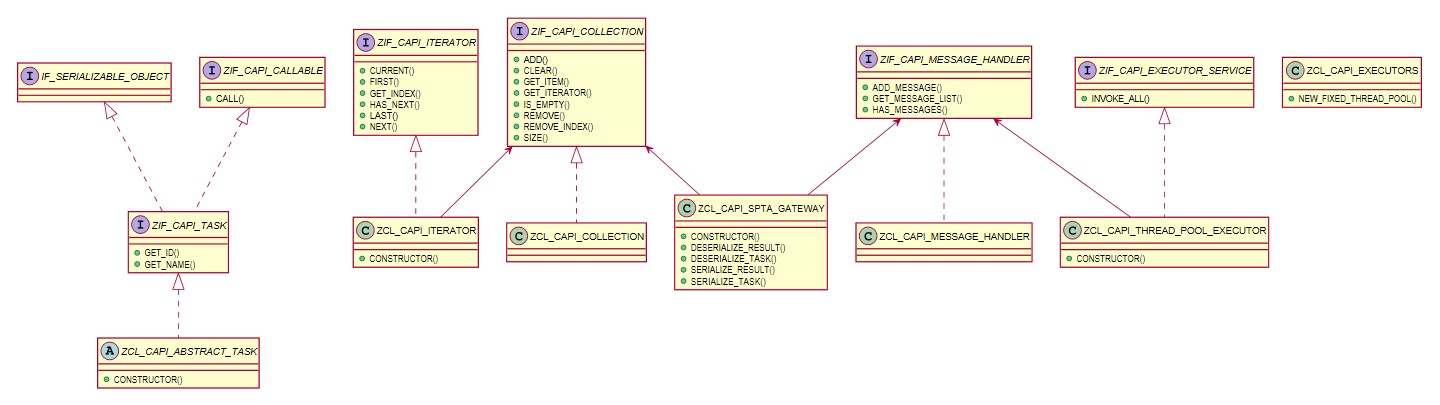
Рис. 1. UML-диаграмма классов ABAP Concurrency API
Использование ABAP Concurrency API позволяет разработчику мыслить более абстрактно. Ему больше не нужно акцентировать внимание на распараллеливании. Вместо этого он может уделить больше времени бизнес-логике своего приложения.
Установка
Проект располагается здесь.
Установка выполняется с помощью abapGit.
Пример использования
Рассмотрим простую задачу.
Необходимо найти квадраты чисел от 1 до 10.
Квадрат каждого из чисел будем искать в отдельном диалоговом процессе (DIA, tcode sm50). Пример оторван от реального мира, но его достаточно для того, чтобы понять, как работать с API.
Для начала создадим 3 класса: Контекст, Задача и Результат.
- lcl_contex, объект этого класса будет инкапсулировать параметры задачи. Использование этого класса не обязательно. Можно обойтись и без него, передав параметры задачи непосредственно в ее конструктор. Однако использование отдельного класса, на мой взгляд, предпочтительнее.
CLASS lcl_context DEFINITION FINAL.
PUBLIC SECTION.
INTERFACES: if_serializable_object.
TYPES: BEGIN OF ty_params,
param TYPE i,
END OF ty_params.
METHODS: constructor IMPORTING is_params TYPE ty_params,
get RETURNING VALUE(rs_params) TYPE ty_params.
PRIVATE SECTION.
DATA: ms_params TYPE ty_params.
ENDCLASS.
CLASS lcl_context IMPLEMENTATION.
METHOD constructor.
ms_params = is_params.
ENDMETHOD.
METHOD get.
rs_params = ms_params.
ENDMETHOD.
ENDCLASS.
- lcl_task описывает объект Задача. Содержит бизнес-логику (в нашем случае возведение числа в степень 2). Обратите внимание, что класс lcl_task наследуется от класса zcl_capi_abstract_task и переопределяет метод zif_capi_callable~call.
CLASS lcl_task DEFINITION INHERITING FROM zcl_capi_abstract_task FINAL.
PUBLIC SECTION.
METHODS: constructor IMPORTING io_context TYPE REF TO lcl_context,
zif_capi_callable~call REDEFINITION.
PRIVATE SECTION.
DATA: mo_context TYPE REF TO lcl_context.
DATA: mv_res TYPE i.
ENDCLASS.
CLASS lcl_task IMPLEMENTATION.
METHOD constructor.
super->constructor( ).
mo_context = io_context.
ENDMETHOD.
METHOD zif_capi_callable~call.
DATA(ls_params) = mo_context->get( ).
mv_res = ls_params-param ** 2.
ro_result = new lcl_result( iv_param = ls_params-param
iv_result = mv_res ).
ENDMETHOD.
ENDCLASS.
- lcl_result описывает Результат выполнения задачи. Этот класс должен реализовывать интерфейс if_serializable_object. В остальном вы можете описать его произвольным образом.
CLASS lcl_result DEFINITION FINAL.
PUBLIC SECTION.
INTERFACES: if_serializable_object.
METHODS: constructor IMPORTING iv_param TYPE i
iv_result TYPE i,
get RETURNING VALUE(rv_result) TYPE string.
PRIVATE SECTION.
DATA: mv_param TYPE i.
DATA: mv_result TYPE i.
ENDCLASS.
CLASS lcl_result IMPLEMENTATION.
METHOD constructor.
mv_param = iv_param.
mv_result = iv_result.
ENDMETHOD.
METHOD get.
rv_result = |{ mv_param } -> { mv_result }|.
ENDMETHOD.
ENDCLASS.
Внимание: объекты классов lcl_task и lcl_result будут сериализованы/десериализованы в процессе выполнения, поэтому избегайте использования статичных атрибутов. Статичные
Если хотите прочитать статью полностью и оставить свои комментарии присоединяйтесь к sapland
ЗарегистрироватьсяУ вас уже есть учетная запись?
Войти
Обсуждения 12
12
Комментарий от
Александр Носов
| 14 апреля 2021, 09:31
1. Может ли библиотека выводить в строке состояния процент выполненных задач?
2. Как насчет распараллеливания пакетного ввода? Там помимо ограничения максимального количества задач нужно проверять еще доступные диалоги, иначе будут дампы если пользователь решит открыть еще один режим во время выполнения параллельных операций.
Комментарий от
Олег Точенюк
| 14 апреля 2021, 11:58
Комментарий от
Виктор Избитский
| 14 апреля 2021, 13:32
Александр Носов 14 апреля 2021, 09:31
Интересная библиотека, Виктор, спасибо. Хочется еще услышать примеры реальных задач и цифр в выигрыше в производительности. Также есть несколько вопросов:
1. Может ли библиотека выводить в строке состояния процент выполненных задач?
2. Как насчет распараллеливания пакетного ввода? Там помимо ограничения максимального количества задач нужно проверять еще доступные диалоги, иначе будут дампы если пользователь решит открыть еще один режим во время выполнения параллельных операций.
На счет примеров задач:
Могу привести примеры из модуля HCM. Пожалуй одна из самых распространенных задач это сбор какой-либо информации по сотрудникам и вывод ее, например, в MS Excel. Т.е. необходимо создать отчет. Время выполнения отчета в основном будет зависеть от количества задействованных процессов, количества обрабатываемых сотрудников и алгоритма считывания информации. Поэтому строгих цифр выигрыша в производительности привести не получится. Все очень зависит от конкретной ситуации. На практике был отчет, который до распараллеливания выполнялся более 4 часов, после распараллеливания ~15 минут.
По вопросам:
1. Да, процент выполненных задач выводится
2. На сколько я понял, вы имеете в виду ноты 734205 и 710920.
Я посмотрел код SPTA Framework'а, который используется в API и в нем, перед вызовом CALL FUNCTION STARTING NEW TASK нет проверки того, что еще есть свободные сеансы пользовательского интерфейса. Т.е. это ограничение стандартного фреймворка, и расширять его пока кажется плохой идеей. Добавил описание этого ограничения в документацию на GitHub.
Комментарий от
Александр Носов
| 14 апреля 2021, 14:02
Виктор Избитский 14 апреля 2021, 13:32
Александр, спасибо за хорошие вопросы.
![]()
На счет примеров задач:
Могу привести примеры из модуля HCM. Пожалуй одна из самых распространенных задач это сбор какой-либо информации по сотрудникам и вывод ее, например, в MS Excel. Т.е. необходимо создать отчет. Время выполнения отчета в основном будет зависеть от количества задействованных процессов, количества обрабатываемых сотрудников и алгоритма считывания информации. Поэтому строгих цифр выигрыша в производительности привести не получится. Все очень зависит от конкретной ситуации. На практике был отчет, который до распараллеливания выполнялся более 4 часов, после распараллеливания ~15 минут.
По вопросам:
1. Да, процент выполненных задач выводится
2. На сколько я понял, вы имеете в виду ноты 734205 и 710920.
Я посмотрел код SPTA Framework'а, который используется в API и в нем, перед вызовом CALL FUNCTION STARTING NEW TASK нет проверки того, что еще есть свободные сеансы пользовательского интерфейса. Т.е. это ограничение стандартного фреймворка, и расширять его пока кажется плохой идеей. Добавил описание этого ограничения в документацию на GitHub.
И еще вопрос, если в zif_capi_callable~call будет вызов MESSAGE TYPE 'S' ***, корректно ли будет статус отображаться (не будут ли мерцания или сброс текста)?
Комментарий от
Виктор Избитский
| 14 апреля 2021, 14:24
Олег Точенюк 14 апреля 2021, 11:58
"избежать существующих сложностей, возникающих при распараллеливании программ в ABAP" - А какие сложности то? Оформить вызов RFC и возвратную процедуру/метод написать? Честно не понял в чем біыли найдены сложности сложности? Ни разу не возникало если честно. Хотя в реальности раза 3 использовал параллельное выполнение.
Т.е. каждый раз приходится реализовывать процесс распараллеливания заново. А если использовать предложенную разработку, этого делать уже не нужно. По большому счету нужно только описать бизнес логику и все.
Может быть как раз из-за описанных проблем вы и использовали параллельное выполнение не так часто? ;-)
Комментарий от
Виктор Избитский
| 14 апреля 2021, 14:37
Александр Носов 14 апреля 2021, 14:02
А где настраивается текст вывода процента выполненных задач?
И еще вопрос, если в zif_capi_callable~call будет вызов MESSAGE TYPE 'S' ***, корректно ли будет статус отображаться (не будут ли мерцания или сброс текста)?
Если в zif_capi_callable~call будет вызов MESSAGE TYPE 'S' ***, то статус будет отображаться корректно. Мерцаний и прочего нет. Т.е. все выглядит так, как-будто сообщения TYPE 'S' игнорируются.
Комментарий от
Александр Носов
| 14 апреля 2021, 16:38
Виктор Избитский 14 апреля 2021, 14:37
Текст вывода процента выполненных задач можно изменить, в отчете ZCONCURRENCY_API. Ищите вызов метода cl_progress_indicator=>progress_indicate.
Если в zif_capi_callable~call будет вызов MESSAGE TYPE 'S' ***, то статус будет отображаться корректно. Мерцаний и прочего нет. Т.е. все выглядит так, как-будто сообщения TYPE 'S' игнорируются.
Комментарий от
Олег Точенюк
| 14 апреля 2021, 19:59
Виктор Избитский 14 апреля 2021, 14:24
Олег, да, перед созданием этого API мне действительно не нравилось то, что вы назвали: для каждого нового отчета приходится создавать RFC ФМ, писать метод/процедуру, обработку ошибок, попытку перезапуска задачи, если, например, случился дамп.
Т.е. каждый раз приходится реализовывать процесс распараллеливания заново. А если использовать предложенную разработку, этого делать уже не нужно. По большому счету нужно только описать бизнес логику и все.
Может быть как раз из-за описанных проблем вы и использовали параллельное выполнение не так часто? ;-)
Опять же если у вас все время пишутся мультипоточные программы, то конечно предложенный вариант удобен. Мне просто, за последние 3 года, адЫн раз пришлось такое делать и то связано это не с ускорением работы, а там просто параллельно процессы в мультимандантной среде запускались из мастер манданта, ну чтобы не тормозить процесс, все запускалось в параллельных процессах.
Но еще раз, в целом если вы делаете это раз в зеленую луну, как я например, то проще выучить синтаксис стандарта и этого вполне достаточно.
Комментарий от
Виктор Избитский
| 14 апреля 2021, 21:10
Олег Точенюк 14 апреля 2021, 19:59
Да нет,, просто не часто приходится переписывать систему, так что ну совсем не хватает производительности. Если случился дамп, то вряд ли перезапуск поможет, так как это что-то серьзное, ну у меня так обычно происходит. Осталное если честно времени особо не занимает, обычно больше времени, опять же у меня, занимает, это перепроектирование программы, которая изначально была расчитана на одни поток, чтобы она стало многопоточной. Ну или изначальное проектирование мультипоточной программы.
Опять же если у вас все время пишутся мультипоточные программы, то конечно предложенный вариант удобен. Мне просто, за последние 3 года, адЫн раз пришлось такое делать и то связано это не с ускорением работы, а там просто параллельно процессы в мультимандантной среде запускались из мастер манданта, ну чтобы не тормозить процесс, все запускалось в параллельных процессах.
Но еще раз, в целом если вы делаете это раз в зеленую луну, как я например, то проще выучить синтаксис стандарта и этого вполне достаточно.
У меня в то же время несколько другой опыт. Довольно часто приходится прибегать к распараллеливанию, чтобы обеспечить разумное время выполнения программы. Отсюда и создание этого API.
Комментарий от
Михаил Сидорочкин
| 26 апреля 2021, 15:50
Комментарий от
Александр Носов
| 15 августа 2021, 10:17
Из плюсов:
1. не надо заморачиваться с созданием ГФ и ФМ для обработки задач
2. не надо заморачиваться с инициализацией группы серверов и следить за наличием ресурсов
3. работать можно не выходя из ОО контекста
Что показалось неудобным:
1. Класс задачи нужно наследовать от базового, это не всегда удобно. Лучше имплементировать интерфейс с методом EXECUTE, содержащий логику выполнения.
2. На мой взгляд много избыточных сущностей: ZCL_CAPI_COLLECTION, ZCL_CAPI_MESSAGE_HANDLER, ZCL_CAPI_EXECUTORS, итератор для чтения результата, контекст....
3. Неудобно что для контекста задачи нужно создавать отдельный класс. Можно ведь брать из контекст из состояния задачи
Пожелание на улучшение. Было бы удобнее чтобы код выглядел примерно так :
DATA lo_tasks TYPE REF TO zcl_capi_collection.
DATA lo_task TYPE REF TO zif_capi_abstract_task. " Содержит только метод EXECUTE
lo_tasks = NEW #( ).
DO 10 TIMES.
lo_task = NEW lcl_task( sy-index ). " LCL_TASK имплементирует ZIF_CAPI_ABSTRACT_TASK
lo_tasks->add_task( lo_task ).
ENDLOOP.
lo_tasks->invoke( ). " Вызывает EXECUTE всех задач, изменяет состояние LCL_TASK
WRITE / lo_tasks->get_result( ). " Измененный результат из состояния LCL_TASK
Комментарий от
Виктор Избитский
| 16 августа 2021, 20:09
Александр Носов 15 августа 2021, 10:17
Появилась задача на распараллеливание, решил попробовать библиотеку на практике. Делюсь впечатлениями.
Из плюсов:
1. не надо заморачиваться с созданием ГФ и ФМ для обработки задач
2. не надо заморачиваться с инициализацией группы серверов и следить за наличием ресурсов
3. работать можно не выходя из ОО контекста
Что показалось неудобным:
1. Класс задачи нужно наследовать от базового, это не всегда удобно. Лучше имплементировать интерфейс с методом EXECUTE, содержащий логику выполнения.
2. На мой взгляд много избыточных сущностей: ZCL_CAPI_COLLECTION, ZCL_CAPI_MESSAGE_HANDLER, ZCL_CAPI_EXECUTORS, итератор для чтения результата, контекст....
3. Неудобно что для контекста задачи нужно создавать отдельный класс. Можно ведь брать из контекст из состояния задачи
Пожелание на улучшение. Было бы удобнее чтобы код выглядел примерно так :
DATA lo_tasks TYPE REF TO zcl_capi_collection.
DATA lo_task TYPE REF TO zif_capi_abstract_task. " Содержит только метод EXECUTE
lo_tasks = NEW #( ).
DO 10 TIMES.
lo_task = NEW lcl_task( sy-index ). " LCL_TASK имплементирует ZIF_CAPI_ABSTRACT_TASK
lo_tasks->add_task( lo_task ).
ENDLOOP.
lo_tasks->invoke( ). " Вызывает EXECUTE всех задач, изменяет состояние LCL_TASK
WRITE / lo_tasks->get_result( ). " Измененный результат из состояния LCL_TASK
1. Абстрактный класс добавлен для того, чтобы каждый раз не реализовывать методы ZIF_CAPI_TASK~GET_ID и ZIF_CAPI_TASK~GET_NAME. Пока не вижу необходимости избавляться от них, т.к. считаю, что они могут быть полезны. Но, если убрать эти методы из интерфейса, то будет ровно то, о чем вы говорите (только вместо метода EXECUTE используется метод CALL).
2. Здесь согласен. Есть некоторая избыточность. Она, в том числе, обусловлена попыткой создать API отдаленно напоминающий java.util.concurrent.*.
Использование ZCL_CAPI_MESSAGE_HANDLER сделал опциональным.
3. Если непосредственно использовать API, то создавать отдельный класс не обязательно. Я об этом упоминал. Но, если использовать реализацию фасада для HCM (пакет ZCAPI_FACADE_HCM), то да,
потребуется создать объект Контекст. Кстати, если вы разрабатываете в другом модуле, то можно создать фасад, учитывающий специфику вашего модуля. Сам паттерн, разумеется, менее гибкий в использовании, но призван упростить взаимодействие с API и отлично подходит для решения типовых задач.
4. Примерно так выглядел прототип API в самом начале :) В текущей реализации, на самом деле, принципиальных отличий от вашего примера нет.