Загрузка «длинных» текстов основных записей материалов при помощи транзакции LSMW. Часть 2.
В этой статье рассмотрен способ загрузки«длинных» текстов для основных записей материалов с помощью транзакции LSMWметодом DirectInput. Под «длинными» текстами понимаются записи, длиной более 132 символов, при этом записи могут содержать символы переноса строк. В основе предлагаемого способа загрузки лежит одновременное использование двух импортируемых структур (двух импортируемых файлов) в одной загрузке.
Связываем данное поле TEXTFORMATи поле TAG2 (Тэг / формат) входной структуры ZLMMD2 (Длинные тексты ОЗМ). Значение этого поля обозначает то, какова будет загружаемая часть длинного текста: будет ли это продолжение предыдущего текста, или данный текст будет перенесен на новую строку, или поставлен по центру. Список и обозначение данных тэгов можно получить, нажав на кнопку F1, поставив курсор в одну из ячеек столбца с тэгами/форматами в редакторе текстов, содержащем длинный текст ОЗМ (данный столбец выделен на Рис. 4). Часть справочного окна выглядит, как представлено на Рис.51.
Рис. 51 Часть справочного окна, описывающего тэги/форматы в редакторе длинных текстов материалов.
Ставим курсор на поле TEXTFORMATи нажимаем кнопку «SourceField» (Рис. 52).
(Рис. 52).
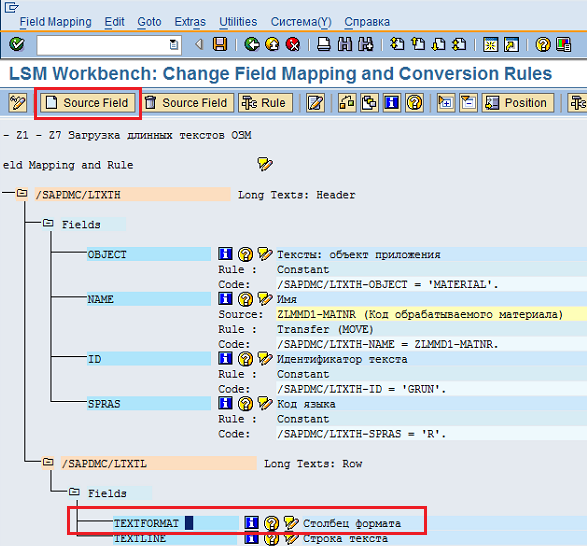
Рис. 52 Выделяем поле TEXTFORMATи нажимаем кнопку "SourceField".
В предложенном списке выбираем поле TAG2 (Тэг / формат строки) структуры ZLMMD2 и нажимаем кнопку «Зеленая галочка»  (Рис. 53).
(Рис. 53).
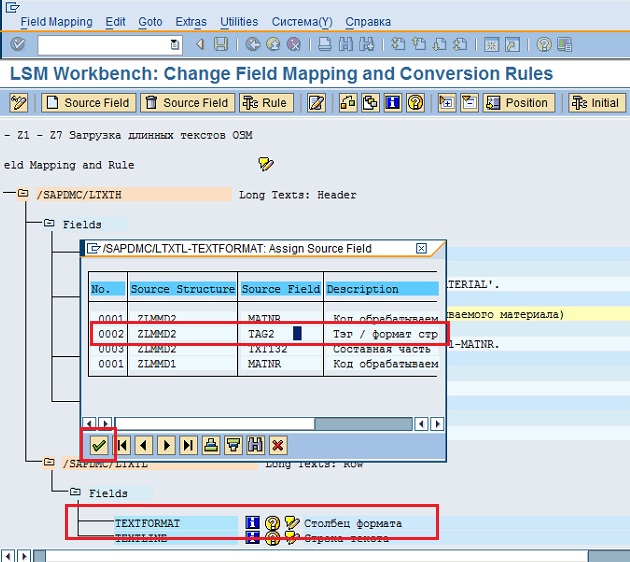
Рис. 53 Связываем поле TEXTFORMATсистемной структуры и поле TAG2 входной структуры ZLMMD2 (Длинные тексты ОЗМ).
Затем переходим к полю TEXTLINE (Строка текста). Ставим на него курсор и нажимаем кнопку «SourceField» (Рис. 54). В этом поле будет содержаться часть длинного текста (часть будет иметь длину максимум 132 символа, а длинный текст в целом может быть в несколько раз больше, чем 132 символа).
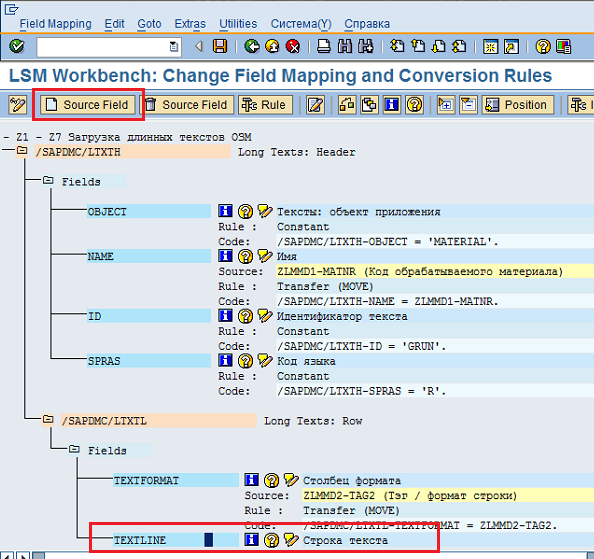
Рис. 54 Задаем источник для поля TEXTLINE.
Задаем связь поля TEXTLINEс полемTXT132 (Составная часть длинного текста)структуры ZLMMD2 (Длинные тексты ОЗМ). Для этого в открывшемся экране ставим курсор на строку, содержащее поле TXT132 и нажимаем кнопку «Зеленая галочка» (Рис. 55).
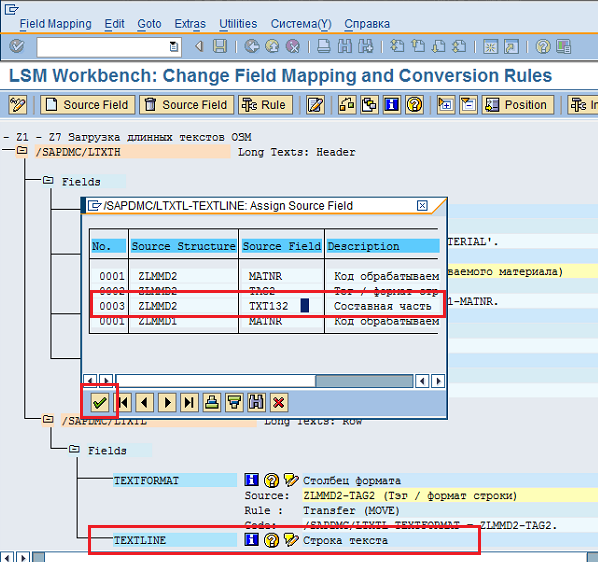
Рис. 55 Связываем поле TEXTLINEсистемной структуры и поле TXT132 входной структуры.
После сделанных изменений экран мэппинга и правил преобразования будет выглядеть так, как представлено на Рис.56.
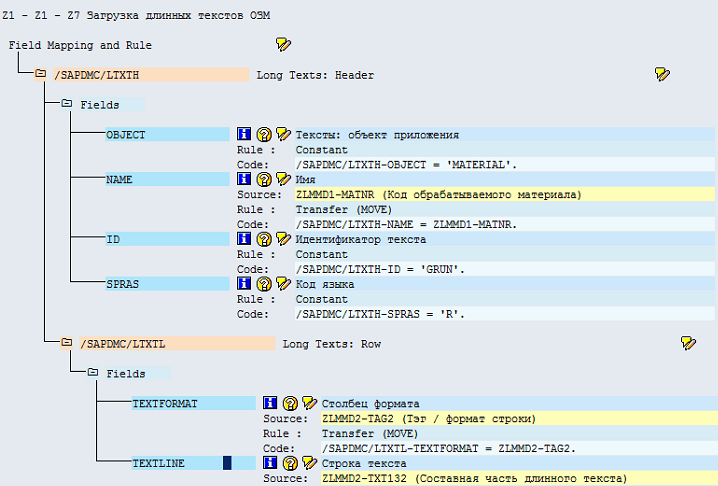
Рис. 56 Итоговый экран мэппинга и правил преобразования для пакетного ввода длинных текстов ОЗМ.
Ответим на вопросы:
- Откуда взялось ограничение по числу символов в «короткой» записи (132)?
- Почему завязка идет именно на это число?
- Почему идет сравнение именно с этим ограничением?
- Зачем использовать 2 входные структуры?
Для этого нажмём дважды на описание поля TEXTLINE (на словосочетание «Строка текста») (Рис. 57).
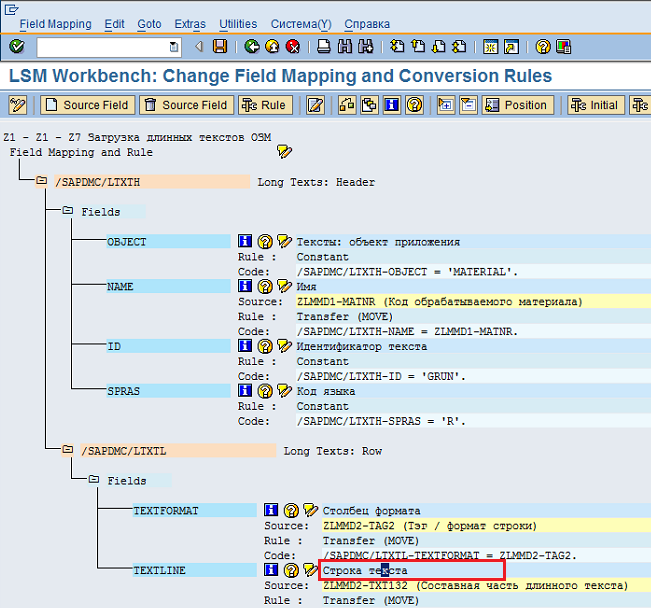
Рис. 57 Щелкаем дважды по "Строке текста" для получения размера данного поля.
Мы видим, что внутри системы данное поле имеет ограничение - 132 символа; то есть за один раз (однократное использованиеструктуры), данное поле сможет «перенести» только 132 символа.
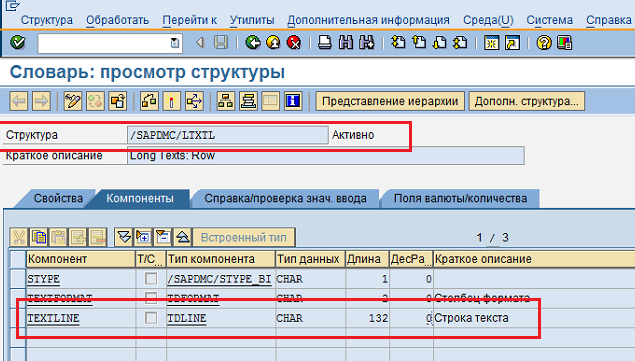
Рис. 58 Ограничение поля TEXTLINEна 132 символ внутри структуры /SAPDMS/LTXTL (LongTexts:Row)
Если мы будем использовать одну общую входную структуру, то чтобы использовать данное поле дважды мы должны дважды осуществить загрузку, при этом вторая загрузка уничтожит результат первой загрузки. Поэтому нам нужно сделать, чтобы в рамках общей пакетной загрузки структура, содержащая непосредственно части длинного текста, использовалась несколько раз; для этого мы и используем дополнительную входную структуру в качестве подчиненной входной структуре по общей загрузке.
Убеждаемся, что экран мэппинга и правил преобразования корректно заполнен. Если все корректно, то нажимаем кнопку «Сохранить»  и выходим в экран со списком этапов на кнопке «Назад»
и выходим в экран со списком этапов на кнопке «Назад»  (Рис.59).
(Рис.59).
Рис. 59 Сохраняем мэппинг и правила преобразования; затем выходим к экрану, содержащему список этапов пакетной загрузки.
Опцию«Maintain fixed values, translations, user-defined routines» пропускаемивыбираемопцию« Specifyfiles». На этом шаге мы будем указывать пути к нашим файлам.
Прежде, чем обозначать пути к файлам, их необходимо создать.
То, как должны отображаться длинные тексты для загружаемых ОЗМ, обозначим в Таблице 2.
Таблица 2 Длинные тексты загружаемых материалов и их особенности.
|
Код материала в системе |
Представление длинного текста |
Комментарий |
|
Z00000000000000001 |
Трехфазный силовой трансформатор с литой изоляцией ТЛС-25 ТУ16 - 2006 ОГГ.670 121.044 ТУ Мощность, кВА: 50 Номинальная частота, Гц: 50 Напряжение ВН, кВ: 6; 6,3; 10; 10,5 |
Длинный текст содержит переход на другую строку. |
|
Z00000000000000002 |
Трехфазный силовой трансформатор с литой изоляцией ТЛС-25 ТУ16 - 2006 ОГГ.670 121.044 ТУ «уточнить по нескольким производителям - комментарий» Мощность, кВА: 50 Номинальная частота, Гц: 50 Напряжение ВН, кВ: 6; 6,3; 10; 10,5 |
Внутри текста должен быть нечитаемый комментарий, который просматривается через редактор текстов. |
|
Z00000000000000003 |
Трехфазный силовой трансформатор с литой изоляцией ТЛС-25… ТУ16 - 2006 ОГГ.670 121.044 ТУ…Мощность, кВА: 50…Номинальная частота, Гц:50… Напряжение ВН, кВ: 6; 6,3; 10; 10,5 |
Длинный текст написан в одной непрерывной строке более чем 132 символа. |
Таким образом, входной файл для структуры ZLMMD1 (Коды материалов)будет выглядеть в Excel, как представлено на Рис. 60.
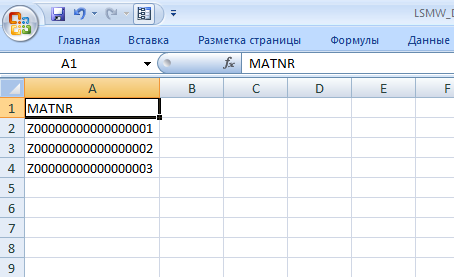
Рис. 60 Формат файла в Excelдля входной структуры ZLMMD1 (Коды материалов).
Входной файл для структуры ZLMMD2 (Длинные тексты ОЗМ)будет выглядеть в Excel, как представлено на Рис. 61. Как видно, он будет больше, так как в нем будет больше записей.
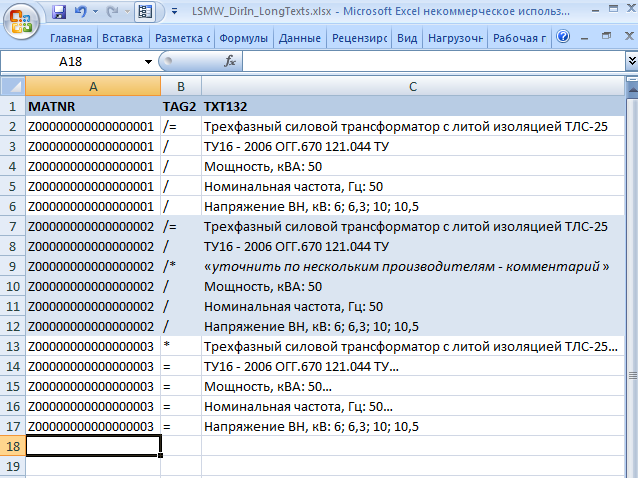
Рис. 61 Формат файла в Excel для входной структуры ZLMMD2 (Длинные тексты ОЗМ).
После преобразования в формат .txtфайлы будут выглядеть, как показано на Рис.62 и 63.
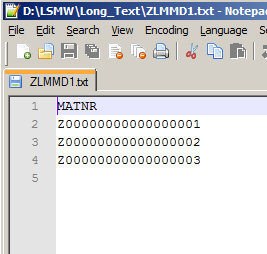
Рис. 62 Формат файла в .txt для входной структуры ZLMMD1 (Коды материалов).
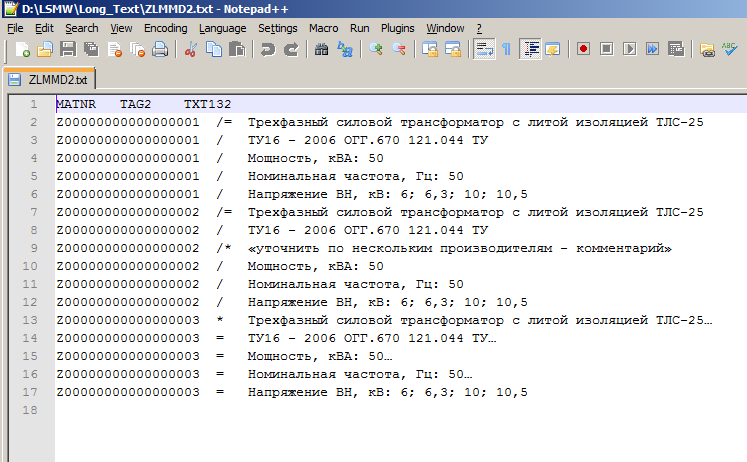
Рис. 63 Формат файла в .txt для входной структуры ZLMMD2 (Длинные тексты ОЗМ).
Теперь свяжем файлы с нашими структурами.
Для этого отметим пункт «Specifyfiles» и нажмём кнопку «Выполнить»  (Рис.64). На данном шаге мы обозначаем пути к файлам на жестком диске компьютера и связываем их с входными структурами в пакетной загрузке.
(Рис.64). На данном шаге мы обозначаем пути к файлам на жестком диске компьютера и связываем их с входными структурами в пакетной загрузке.
Рис. 64 Запускаем этап "Specifyfiles".
В открывшемся экране переходим в режим изменения с помощью кнопки «Очки/Карандаш»  (Рис. 65).
(Рис. 65).
Рис. 65 Переходим в режим изменения для указания пути к файлу.
Дваждыщёлкаемпостроке Legacy Data On the PC (Frontend) (Рис. 65).
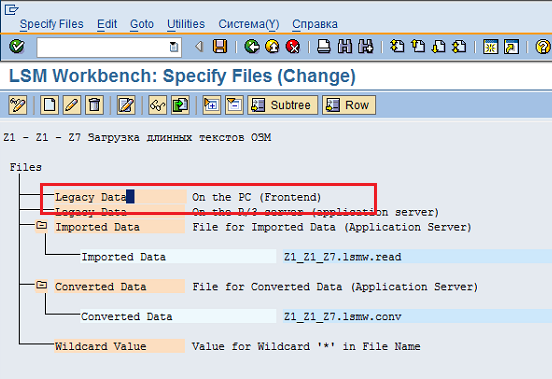
Рис. 66 Для указания пути к файлу дважды щёлкаем по строке LegacyDataOnthePC (Frontend).
На каком бы языке не открылся экран, нам необходимо указать путь к файлу, краткое описание, указать, что разделителем является Tabulator, а также поставить галочки, что имена полей также содержится в наших файлах в первой строке. Поля и флажки, на которые необходимо обратить внимание, обозначены на Рис.67. После заполнения нажимаем «Зеленую галочку» .
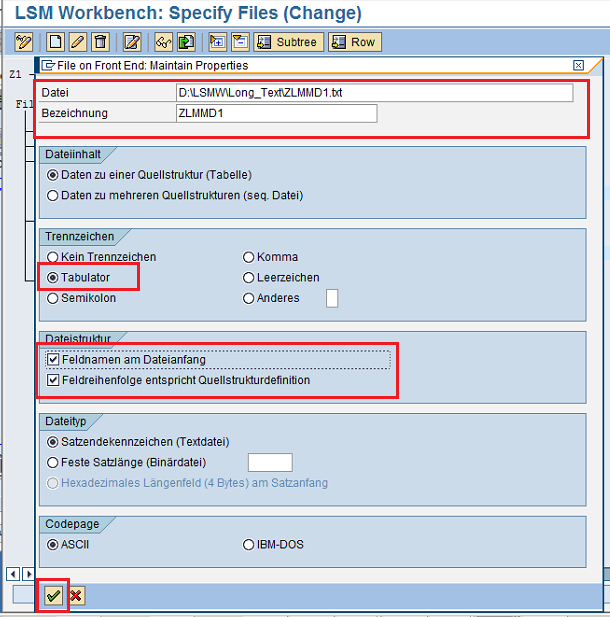
Рис. 67 Определяем параметры файла, который будет считываться.
Затем курсор должен остаться на строке LegacyDataOnthePC (Frontend), и необходимо нажать на кнопку «Создать»  , чтобы обозначить путь ко второму файлу (Рис. 68).
, чтобы обозначить путь ко второму файлу (Рис. 68).
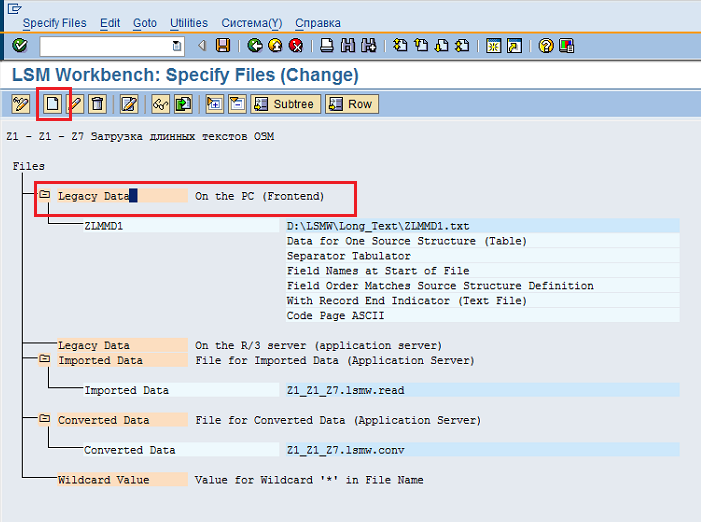
Рис. 68 Обозначаем путь к файлу, содержащий данные для подчиненной структуры ZLMMD2 (Длинные тексты ОЗМ)
Как и в случае с основной структурой, заполняем поля и выбираем опции, как это обозначено на рисунке 69.
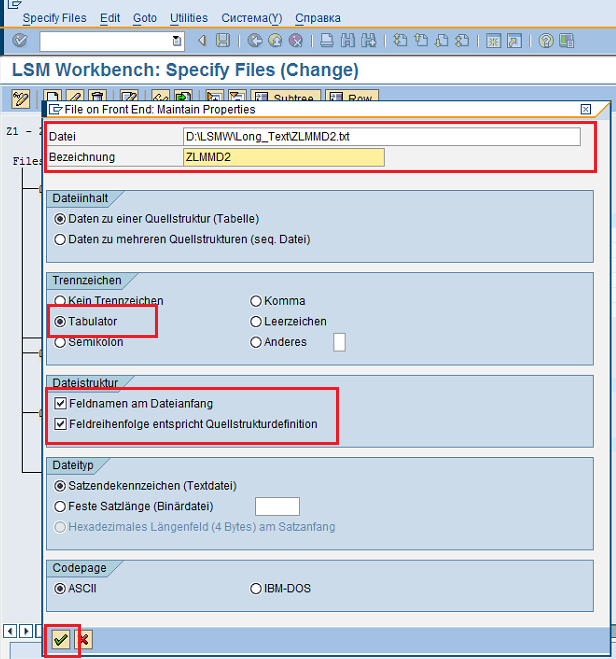
Рис. 69 Обозначаем параметры входного файла, который должен быть связан с подчиненной структурой.
После указания путей к нескольким файлам будем иметь экран, представленный на Рис.70.
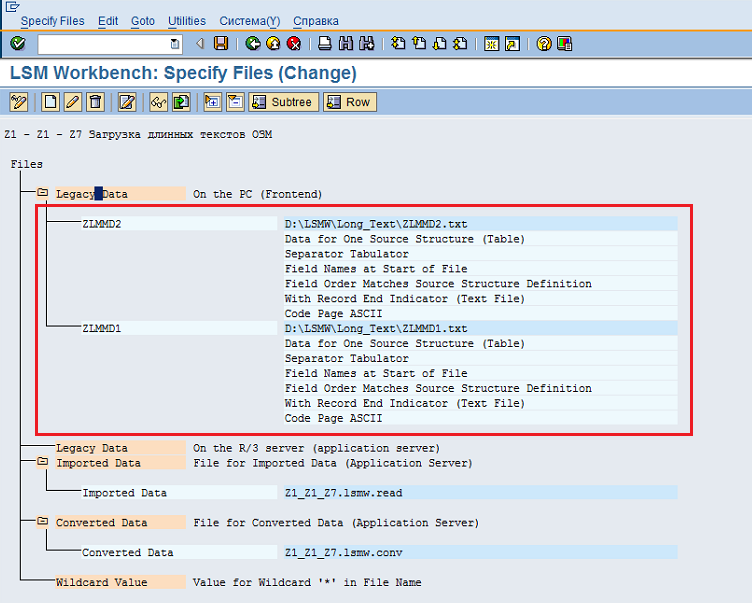
Рис. 70 Обозначение путей к двум файлам.
Убеждаемся в том, что пути заданы корректно. Если все корректно, то нажимаем кнопку «Сохранить» и выходим в экран со списком опций, нажав на кнопку
Если хотите прочитать статью полностью и оставить свои комментарии присоединяйтесь к sapland
ЗарегистрироватьсяУ вас уже есть учетная запись?
Войти
Обсуждения 17
17
Комментарий от
Олег Башкатов
| 16 февраля 2013, 10:55
Также в комментариях освещаются альтернативные способы загрузки длинных текстов к основной записи материала.
В комментариях к первой части приводится текст кода оптимизированной программы, уже готовой к использованию. Импорт программы в систему занимает не более минуты с учетом наличия ключа разработчика (sapland.ru/articles/stats/2013/1/zagruzka-dlinnih-tekstov-osnovnih-zapisei-materialov-pri-pomoschi-tranzaktsii-ls.html#comment-1514).
Рекомендованная последовательность действий:
1) Текст указанной программы должен быть сохранён в файле .txt с кодировкой UTF-8 на ПК консультанта;
2) Транзакция se38: указываем имя программы, нажимаем создать; далее указываем заголовок программы (свободный текст), тип (можно: "1 Выполняемыя программа"), Статус (можно: "K продуктивная программа клиента"), Приложение (можно "M Управление материальными потоками")); нажимаем сохранить; указываем пакет (скорее всего, в системе уже будет создан Z-пакет для целей разработок текущего проекта; если его нет, то предварительно создать ) и создаём запрос.
3) В меню выбираем Утилиты -> Другие утилиты -> Загрузка/Выгрузка -> Загрузка -> [выбираем файл на жёстком диске].
4) сохраняем и проверяем.
Формат загрузки показан на рисунке 63 без заголовка. Первая строка файла - это данные для загрузки, а не наименование столбцов. Поэтому из текстового файла на рисунке 63 нужно удалить строку, содержащую: MATNR TAG2 TXT132. Данные в строке разделены между собой символами tab.
В комментариях к первой части статьи консультанты при обсуждении решения допустили определённую вольность речи в силу того, что они не равнодушны к своей работе; данную вольность они не при каких обстоятельствах не позволят себе в общении с заказчиком и пользователями.
После прочтения данной статьи и комментариев, проблем с загрузкой длинных текстов к любому объекту SAP ERP возникнуть не должно. В этом ценность статьи и комментариев.
Автор статьи очень благодарит Олега Виталиевича Точенюк за предоставленный исходный код оптимально написанной программы ABAP.
Комментарий от
Олег Точенюк
| 16 февраля 2013, 22:32
Олег Башкатов 16 февраля 2013, 10:55
В данной статье подробно рассматривается метод Direct Input для загрузки длинных текстов.
Также в комментариях освещаются альтернативные способы загрузки длинных текстов к основной записи материала.
В комментариях к первой части приводится текст кода оптимизированной программы, уже готовой к использованию. Импорт программы в систему занимает не более минуты с учетом наличия ключа разработчика (sapland.ru/articles/stats/2013/1/zagruzka-dlinnih-tekstov-osnovnih-zapisei-materialov-pri-pomoschi-tranzaktsii-ls.html#comment-1514).
Рекомендованная последовательность действий:
1) Текст указанной программы должен быть сохранён в файле .txt с кодировкой UTF-8 на ПК консультанта;
2) Транзакция se38: указываем имя программы, нажимаем создать; далее указываем заголовок программы (свободный текст), тип (можно: "1 Выполняемыя программа"), Статус (можно: "K продуктивная программа клиента"), Приложение (можно "M Управление материальными потоками")); нажимаем сохранить; указываем пакет (скорее всего, в системе уже будет создан Z-пакет для целей разработок текущего проекта; если его нет, то предварительно создать ) и создаём запрос.
3) В меню выбираем Утилиты -> Другие утилиты -> Загрузка/Выгрузка -> Загрузка -> [выбираем файл на жёстком диске].
4) сохраняем и проверяем.
Формат загрузки показан на рисунке 63 без заголовка. Первая строка файла - это данные для загрузки, а не наименование столбцов. Поэтому из текстового файла на рисунке 63 нужно удалить строку, содержащую: MATNR TAG2 TXT132. Данные в строке разделены между собой символами tab.
В комментариях к первой части статьи консультанты при обсуждении решения допустили определённую вольность речи в силу того, что они не равнодушны к своей работе; данную вольность они не при каких обстоятельствах не позволят себе в общении с заказчиком и пользователями.
После прочтения данной статьи и комментариев, проблем с загрузкой длинных текстов к любому объекту SAP ERP возникнуть не должно. В этом ценность статьи и комментариев.
Автор статьи очень благодарит Олега Виталиевича Точенюк за предоставленный исходный код оптимально написанной программы ABAP.
2. В довесок к LSMW, к сожалению метод Direct Input реализован не для всех объектов системы, вот известный мне список реализаций прямого ввода:
RFBISA00 -> GL A/C Master Record
RCSBI010 -> Create Material BOM
RCSBI020 -> Change Material BOM
RM06IBI0 -> Purchasing info record.
RM06BBI0 -> Purchase requisition
RM06EEI0 -> Purchase Order
RFBIKR00 -> Vendor Master
RFBIDE00 -> Customer master
RVINVB10 -> Sales documents
RM07MMBL -> Goods movement
RFBIBL00 -> Financial documents
RAALTD11 -> Fixed Assets
RCPTRA02 -> Routing
RCRAPDX2 -> Work center
RPUSTD00 -> HR master data
RHALTD00 -> Personnel Planning
Комментарий от
Олег Башкатов
| 16 февраля 2013, 23:45
Олег Точенюк 16 февраля 2013, 22:32
1. Типа поговорили :-), вообще-то код не оптимизированный, а просто код для загрузки текстов ОЗМ.
2. В довесок к LSMW, к сожалению метод Direct Input реализован не для всех объектов системы, вот известный мне список реализаций прямого ввода:
RFBISA00 -> GL A/C Master Record
RCSBI010 -> Create Material BOM
RCSBI020 -> Change Material BOM
RM06IBI0 -> Purchasing info record.
RM06BBI0 -> Purchase requisition
RM06EEI0 -> Purchase Order
RFBIKR00 -> Vendor Master
RFBIDE00 -> Customer master
RVINVB10 -> Sales documents
RM07MMBL -> Goods movement
RFBIBL00 -> Financial documents
RAALTD11 -> Fixed Assets
RCPTRA02 -> Routing
RCRAPDX2 -> Work center
RPUSTD00 -> HR master data
RHALTD00 -> Personnel Planning
В любом случае, называйте как хотите - Ваш код :-)
На мой взгляд, в SAP нет панацеи в принципе. И уж тем более, LSMW не претендует на это звание, даже в части пакетной загрузки.
Особенно, если понимать SAP в широком смысле, а не только SAP ERP.
Цель моих статей про LSWM - рассказать про использование этого инструмента.
Решение о его эффективности каждый консультант будет принимать самостоятельно. я считаю, что на проектах достаточное количество случаев, когда инструмент LSMW эффективен; конечно, много случаев когда лучше использовать другие подходы.
PS. а тексты не считаются?
это не в довесок к LSMW, в довесок к LSWM Direct Input. Помимо Direct Input, с готовыми структурами еще есть BAPI и IDOC.
PPS. Проясните, пожалуйста, с отчеством.
Комментарий от
Николай Авданкин
| 28 февраля 2013, 10:21
Все очень наглядно и понятно.
LSMW конечно не идеален и к нему нужно приловчиться, но считаю что лучше использвоать этот стандартный инструмент, чем писать программы загрузки под каждый конкретный случай, которые требуют и немалых знаний ABAP и хорошего тестирования.
Комментарий от
неизвестного пользователя
| 20 марта 2014, 14:29
Комментарий от
Сергей Маслов
| 27 мая 2014, 18:46
Выполнил все шаги, все работает.
Комментарий от
Ольга Петрова
| 19 февраля 2016, 13:12
Комментарий от
Роман Конышев
| 24 декабря 2017, 09:06
Олег Башкатов 16 февраля 2013, 23:45
LSMW порождает код. По сравнению с "порожденным кодом от LSMW" Ваш код я назвал оптимизированным. Поэтому такое слово.
В любом случае, называйте как хотите - Ваш код :-)
На мой взгляд, в SAP нет панацеи в принципе. И уж тем более, LSMW не претендует на это звание, даже в части пакетной загрузки.
Особенно, если понимать SAP в широком смысле, а не только SAP ERP.
Цель моих статей про LSWM - рассказать про использование этого инструмента.
Решение о его эффективности каждый консультант будет принимать самостоятельно. я считаю, что на проектах достаточное количество случаев, когда инструмент LSMW эффективен; конечно, много случаев когда лучше использовать другие подходы.
PS. а тексты не считаются?
это не в довесок к LSMW, в довесок к LSWM Direct Input. Помимо Direct Input, с готовыми структурами еще есть BAPI и IDOC.
PPS. Проясните, пожалуйста, с отчеством.
прошу прощения, а как можно создать "подробное описание" при создании Сообщений посредству Direct Input с использованием LSMW?
Если в настройках определен диапазон номеров, и при создании Сообщений, код Сообщения присваивается системой, то описанный Вами 2-х уровневый метод не подойдёт. Можете мне помочь консультацией?
С уважением, Роман
Комментарий от
Олег Башкатов
| 26 декабря 2017, 09:57
Роман Конышев 24 декабря 2017, 09:06
Добрый день,
прошу прощения, а как можно создать "подробное описание" при создании Сообщений посредству Direct Input с использованием LSMW?
Если в настройках определен диапазон номеров, и при создании Сообщений, код Сообщения присваивается системой, то описанный Вами 2-х уровневый метод не подойдёт. Можете мне помочь консультацией?
С уважением, Роман
про какое сообщение речь - про Сообщение ТОРО? (IW21 / IW22 / IW23) ?
1) Вам необязательно объединять по номеру материала или сообщения два уровня.
Вы можете создать поле в структурах (1го уровня и 2го уровня), которое будете использовать для объединения.
2) можно загрузку сделать в два шага: загрузка сообщений, загрузка текстов к сообщениям.
С Новым годом!
Комментарий от
Роман Конышев
| 27 декабря 2017, 09:33
Олег Башкатов 26 декабря 2017, 09:57
Добрый день, Роман
про какое сообщение речь - про Сообщение ТОРО? (IW21 / IW22 / IW23) ?
1) Вам необязательно объединять по номеру материала или сообщения два уровня.
Вы можете создать поле в структурах (1го уровня и 2го уровня), которое будете использовать для объединения.
2) можно загрузку сделать в два шага: загрузка сообщений, загрузка текстов к сообщениям.
С Новым годом!
Да, я говорил именно про Сообщения ТОРО.
Дело в том, что при создании Сообщений используется автоматическая генерация кода Сообщения из указанного диапазона. Таким образом,в LSMW мы не указывает номер создаваемого Сообщения. В таком случае, второй уровень в структуре не спасёт.
Делать загрузку в два шага- в случае большого количества информации- так же не вариант. В таком случае придётся разбивать шаблон на множество полей для ввода длинного текста, с определенным количеством знаков в каждой ячейке, что то же не удобно.
Есть ли какое то ещё решение?
видимо придётся привлекать разработчика к данной проблеме.
С уважением,
Роман
С наступающим НГ!!!
Комментарий от
Олег Точенюк
| 27 декабря 2017, 23:04
Роман Конышев 27 декабря 2017, 09:33
Добрый день, Олег.
Да, я говорил именно про Сообщения ТОРО.
Дело в том, что при создании Сообщений используется автоматическая генерация кода Сообщения из указанного диапазона. Таким образом,в LSMW мы не указывает номер создаваемого Сообщения. В таком случае, второй уровень в структуре не спасёт.
Делать загрузку в два шага- в случае большого количества информации- так же не вариант. В таком случае придётся разбивать шаблон на множество полей для ввода длинного текста, с определенным количеством знаков в каждой ячейке, что то же не удобно.
Есть ли какое то ещё решение?
видимо придётся привлекать разработчика к данной проблеме.
С уважением,
Роман
С наступающим НГ!!!
Комментарий от
Олег Башкатов
| 28 декабря 2017, 08:18
Роман Конышев 27 декабря 2017, 09:33
Добрый день, Олег.
Да, я говорил именно про Сообщения ТОРО.
Дело в том, что при создании Сообщений используется автоматическая генерация кода Сообщения из указанного диапазона. Таким образом,в LSMW мы не указывает номер создаваемого Сообщения. В таком случае, второй уровень в структуре не спасёт.
Делать загрузку в два шага- в случае большого количества информации- так же не вариант. В таком случае придётся разбивать шаблон на множество полей для ввода длинного текста, с определенным количеством знаков в каждой ячейке, что то же не удобно.
Есть ли какое то ещё решение?
видимо придётся привлекать разработчика к данной проблеме.
С уважением,
Роман
С наступающим НГ!!!
по ссылке проработал вопрос
yadi.sk/i/fnOZrIth3R3VE7
это то, что Вам нужно?
+ присоединяюсь к Олегу.
итого: 3 решения :-)
Комментарий от
Олег Башкатов
| 28 декабря 2017, 08:39
Олег Башкатов 28 декабря 2017, 08:18
Роман,
по ссылке проработал вопрос
yadi.sk/i/fnOZrIth3R3VE7
это то, что Вам нужно?
+ присоединяюсь к Олегу.
итого: 3 решения :-)
возможно, что-то не совсем корректно пояснено.
Комментарий от
Роман Конышев
| 28 декабря 2017, 09:37
Олег Башкатов 28 декабря 2017, 08:39
если что-то непонятно - сообщайте. я сделал упрощенный пример на той системе и тех данных, которые были под рукой.
возможно, что-то не совсем корректно пояснено.
большое спасибо!
да, теперь понятно.
С уважением,
Роман
Комментарий от
Ирина Михайлова
| 18 января 2023, 10:31
Комментарий от
Ирина Михайлова
| 18 января 2023, 10:33
Ирина Михайлова 18 января 2023, 10:31
Спасибо, сделала загрузку LSMW, все работает!
Комментарий от
Олег Башкатов
| 18 января 2023, 19:41
Ирина Михайлова 18 января 2023, 10:33
Теперь вопрос, как извлечь эти данные, где они хранятся?
с помощью функционального модуля READ_TEXT.
(этот самый универсальный способ для длинных текстов любых объектов).
То есть если в удобном виде выгружать на постоянной основе - то придется написать свою custom-программу с использованием ФМ READ_TEXT.
чтобы точно установить параметры ФМа: поставьте точку останова в начале модуля READ_TEXT и зайдите в материал с длинным текстом и откройте экран с длинным текстом; таким образом, увидите параметры.
Для примера из статьи
OBJECT - Константа MATERIAL
NAME - Номер материала (если материал цифровой - то с ведущими нулями впереди)
ID - Константа GRUN (для текстов из основных данных)
SPRAS - для языка RU - R, для EN - E; для остальных языков перекодировка в таблице T002
Если нужно единоразово для материалов (например, просто для проверки) - то можно использовать программу RMDATGEN и на селекционном экране указать выгрузка файл на ПК.
На вопрос "где хранятся":
Информация о длинных текстах хранится в двух системных таблица STXH и STXL. Сами длинные хранятся в таблице STXL, но через SE16(N/H/*) Вы их не увидите, так как сами данные в бинарном виде.